A naukri.com initiative
Dev
7d
87
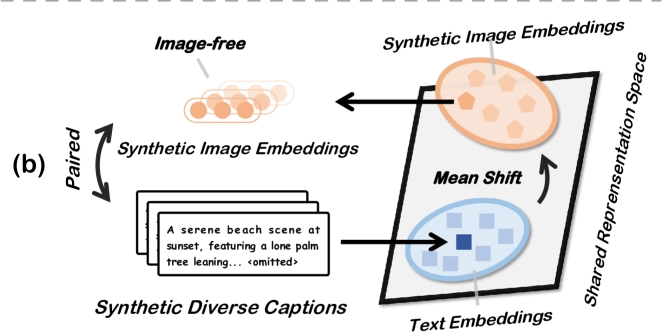
Image Credit: Dev
AI Breakthrough: Training Vision Models Without Images Cuts Computing Costs by 37x
- Unicorn synthesizes text-only data for training Vision Language Models (VLMs)
- Eliminates need for image generation during training
- Reduces computational cost by 37x compared to methods using synthetic images
- Proves VLMs can learn visual concepts from purely textual data
Read Full Article
5 Likes
For uninterrupted reading, download the app