A naukri.com initiative
Dev
1M
273
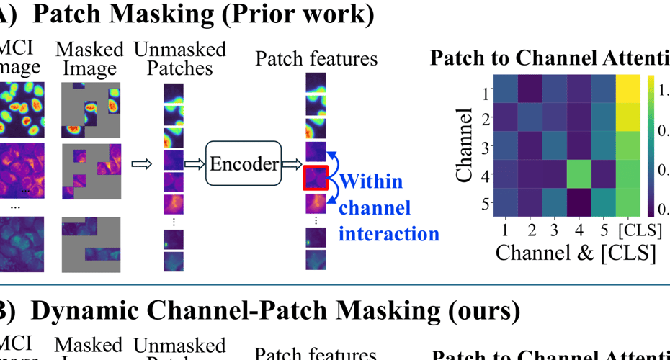
Image Credit: Dev
AI Model Achieves 99% Accuracy in Satellite Image Analysis Using Channel-Aware Learning
- ChA-MAEViT unifies masked autoencoder pretraining with multi-channel vision transformers
- Introduces two key innovations: channel-aware masking and channel-specific embedding layers
- Achieves state-of-the-art performance on hyperspectral image classification and remote sensing
- Reduces the need for extensive labeled data through effective self-supervised pretraining
Read Full Article
16 Likes
For uninterrupted reading, download the app