A naukri.com initiative
Towards Data Science
1w
148
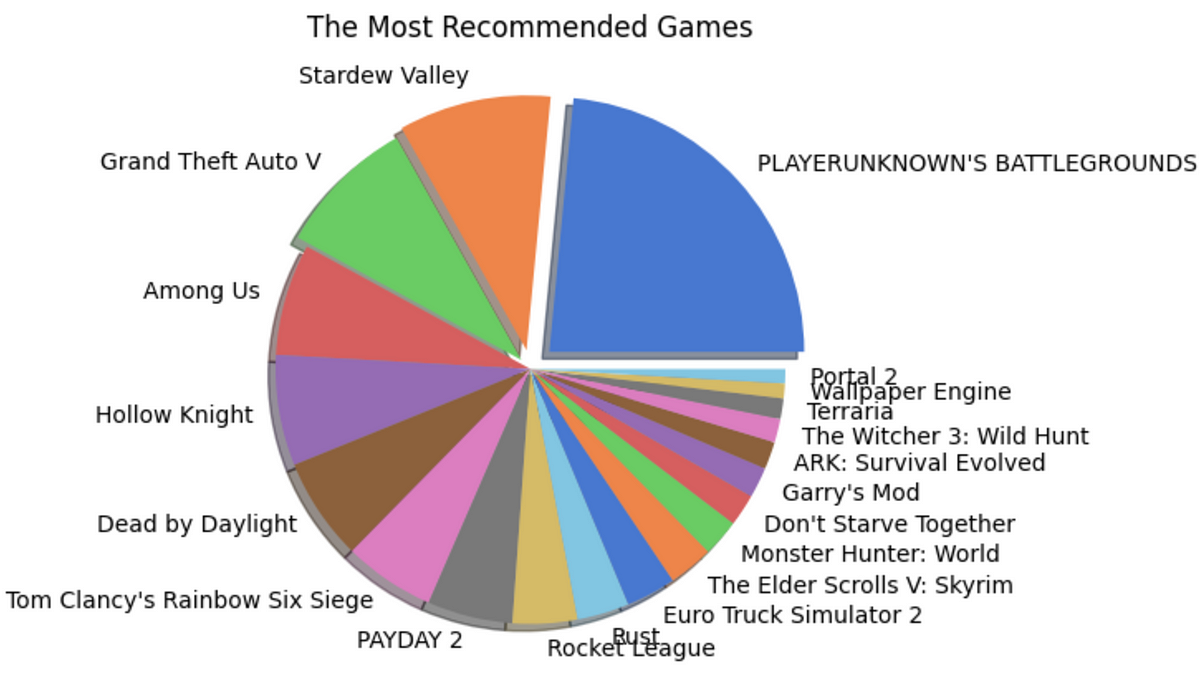
Image Credit: Towards Data Science
Apache Hadoop and Apache Spark for Big Data Analysis
- The article explains the installation of Hadoop Distributed File System, Apache Spark and PySpark on a macOS using Homebrew.
- The author uses the Steam Reviews Dataset 2021 with 21.7 million rows and 23 columns for demonstrating the use of HDFS and analysis of Big Data.
- The author uses PySpark library to access, clean and analyze the dataset to find demography, sentiment analysis and game recommendation.
- The article uses the PySpark show() function to briefly go through the dataset and proceeds to remove the reviews column in the dataset. The column had multiple languages making any sentiment analysis difficult.
- The dataset had 23 variable names presented in a format not acceptable as a Python identifier. The date and time attributes were also in a different data type and had to be changed accordingly.
- The dataset is split into different PySpark data frames to analyze the data from different perspectives.
- The article focuses on understanding review and recommendation patterns for different games. It further shows how to determine popular languages used for review and languages used by reviewers of popular games and to use this trend to determine the demographic influence and sentiments of the players to be used for recommending new games in the future.
- The article details the implementation of the Alternating Least Squares (ALS) machine-learning algorithm from the Spark ML Library to recommend games based on player’s behavior.
- The implemented algorithm identified the game selection pattern for players who play each available game on the Steam App.
- In conclusion, the article successfully implements the installation of Hadoop Distributed File System, Apache Spark and PySpark on a macOS and demonstrates how to analyze a Big Data using PySpark. The Steam Reviews Dataset 2021 is used for demonstrating the use of HDFS and analysis of Big Data.
Read Full Article
8 Likes
For uninterrupted reading, download the app