A naukri.com initiative
Towards Data Science
1M
233
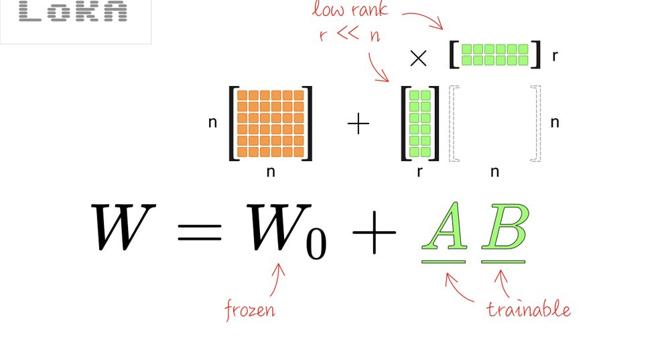
Image Credit: Towards Data Science
Are You Still Using LoRA to Fine-Tune Your LLM?
- LoRA, a method for fine-tuning language models with a smaller set of trainable parameters, has gained popularity and integration into mainstream ML frameworks like Keras.
- Researchers are exploring alternatives to LoRA, with a focus on leveraging singular value decomposition (SVD) to select smaller 'adapter' matrices for efficient training.
- SVD splits a matrix into three components: U, S, and V, enabling efficient matrix analysis and manipulation.
- Several recent SVD-based low-rank fine-tuning techniques have emerged, such as SVF and SVFT, focusing on optimizing matrix singular values for training.
- Techniques like PiSSA and MiLoRA propose tuning only specific subsets of singular values to improve fine-tuning efficiency and avoid overfitting.
- LoRA-XS represents a variation of these techniques, offering results comparable to PiSSA but with fewer parameters.
- Exploration of singular value properties questions the practicality of categorizing them as 'large' and 'small' for fine-tuning purposes.
- Transformer models like SVF and SVFT provide parameter-efficient alternatives to LoRA, offering flexibility in tuning while maintaining model performance.
- In conclusion, adopting SVD-based techniques like SVF can lead to more efficient fine-tuning processes while achieving desired model outcomes with reduced parameter sets.
- Further research is ongoing in the field of low-rank fine-tuning methods to enhance the effectiveness of training large language models.
Read Full Article
12 Likes
For uninterrupted reading, download the app