A naukri.com initiative
Medium
2M
247
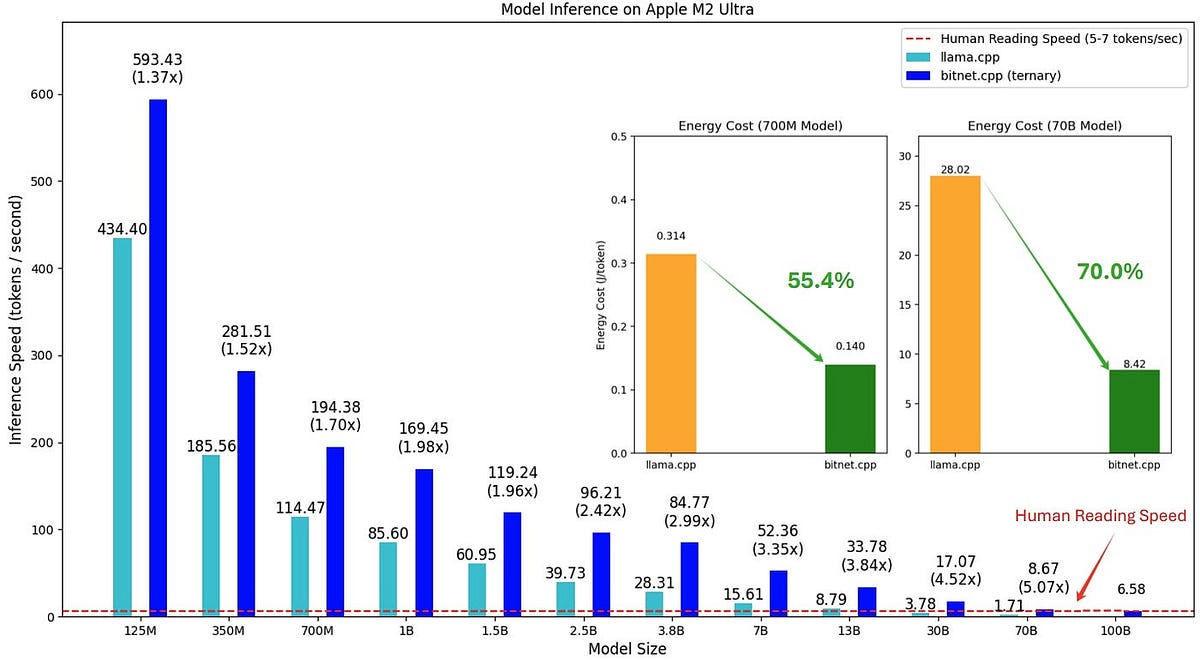
Image Credit: Medium
BitNet a4.8: Microsoft’s Leap Toward Ultra-Efficient AI
- BitNet a4.8 introduces 4-bit activations to enhance computational efficiency in AI while maintaining model accuracy.
- The hybrid quantization and sparsification strategy of BitNet a4.8 applies 4-bit quantization to inputs and sparsifies intermediate states to mitigate quantization errors.
- Microsoft provides the bitnet.cpp framework for developers to explore the open source inference framework supporting fast and lossless inference of 1.58-bit models on CPUs.
- BitNet a4.8 signifies a significant leap towards efficient and accessible AI, addressing quantization errors and computational demands for broader adoption of LLMs.
Read Full Article
14 Likes
For uninterrupted reading, download the app