A naukri.com initiative
Medium
2d
243
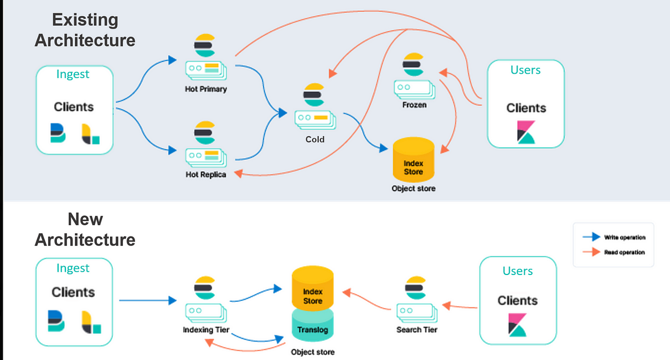
Image Credit: Medium
Comprehensive Guide to Choosing the Right Database for RAG Implementation: Leveraging…
- To implement RAG, one must first choose the right database for information retrieval, which could be Elasticsearch, vector databases, or knowledge graphs.
- Elasticsearch is ideal for structured data like CIM tables that require fast and accurate retrieval.
- Vector databases work best with large amounts of unstructured data and semantic search.
- Knowledge graphs are best suited for complex, interconnected relationship scenarios where a deep understanding is needed to retrieve the right information.
- Optimizing RAG systems revolves around enhancing performance dimensions like query latency, retrieval speed, and data accuracy.
- Multi-retrieval strategies involve leveraging parallel searches across different databases to maximize retrieval quality and speed.
- Multi-database retrieval pipeline where each database contributes its strengths in the context of specific queries leads to an effective RAG system.
- Choosing the right database for a RAG system depends on the type of data and queries being answered.
- Ultimately, the future of RAG lies in integrating multiple databases for structured and unstructured data, complex relationships, and highly accurate results.
- By understanding the strengths and limitations of each database, a system that leverages the best features of each can be built.
Read Full Article
14 Likes
For uninterrupted reading, download the app