A naukri.com initiative
Hackernoon
1M
31
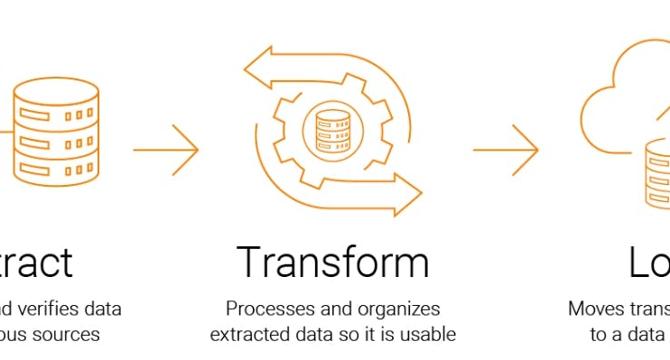
Image Credit: Hackernoon
Data Transformation and Discretization: A Comprehensive Guide
- Data transformation and discretization are crucial in the data preprocessing pipeline, converting raw data into suitable forms for analysis and improving the accuracy of mining algorithms.
- Data transformation strategies include smoothing, attribute construction, aggregation, normalization, and discretization.
- Normalization scales data attributes to specific ranges, enhancing the performance of distance-based mining algorithms.
- Techniques like Min-Max Normalization, Z-Score Normalization, and Decimal Scaling Normalization are commonly used for normalization.
- Discretization replaces numeric values with intervals or labels to simplify data and aid in pattern recognition.
- Binning, histogram analysis, and concept hierarchy generation are key techniques in discretization to organize data into groups or intervals.
- Clusters, decision trees, and correlation analyses assist in discretization by grouping similar values, splitting attributes into intervals, and merging intervals with similar distributions.
- Concept hierarchies generalize nominal attributes to higher-level concepts like street to city to country, aiding in data understanding.
- Practical applications include customer segmentation, market basket analysis, and fraud detection using data transformation and discretization techniques.
- Data transformation and discretization are fundamental for enhancing data quality, mining efficiency, and deriving valuable insights from raw data.
Read Full Article
1 Like
For uninterrupted reading, download the app