A naukri.com initiative
Medium
1w
127
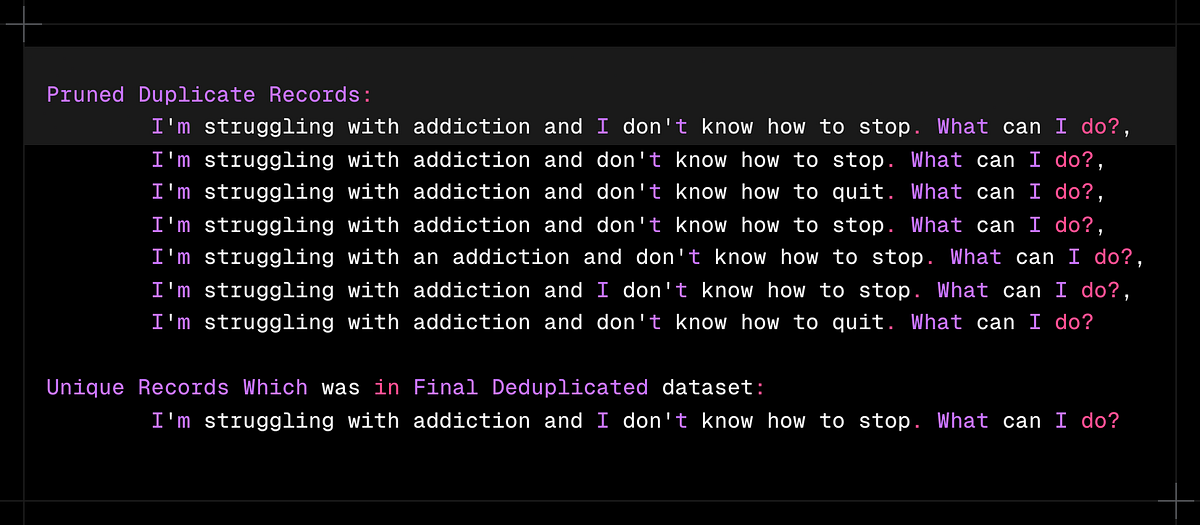
Image Credit: Medium
Effective Data Deduplication for Training Robust Language Models
- Duplicate entries in training datasets can lead to over-fitting and give an illusion of better performance during training.
- Deduplication is key to unbiased model training and ensures that the model encounters a diverse range of examples.
- Lexical deduplication targets exact or near-exact matches, while semantic deduplication goes deeper by finding texts that are similar in meaning.
- By implementing both lexical and semantic deduplication techniques, the dataset's quality is enhanced, leading to more robust and generalizable language models.
Read Full Article
7 Likes
For uninterrupted reading, download the app