A naukri.com initiative
Medium
2M
248
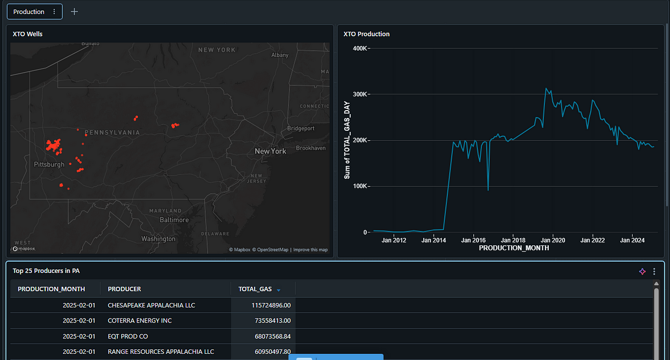
Image Credit: Medium
From Shale to Scale: Wrangling Oil & Gas Data with GCP and Databricks
- The article discusses using GCP and Databricks to analyze Oil & Gas data, particularly focusing on Pennsylvania production data available from 1980 to February 2025.
- By uploading data to GCP buckets and utilizing Databricks, the article explains how to clean, combine, and analyze large datasets at scale.
- The project involves working with production data for each well and inventory data for each producer, totaling about 14 Excel files with 1.06 GB of data.
- Creating a GCP storage bucket, setting up access for Databricks, and organizing data into clean tables are key steps in the process.
- The article also covers generating visualizations like maps using Plotly and Folium, and creating interactive dashboards on Databricks.
- The dashboard showcases well locations, monthly production, and top producers, demonstrating the value of leveraging public data and powerful tools for insights.
- The project highlights the transformation of unstructured data into actionable insights through cloud storage, PySpark, and Databricks.
- It encourages exploration of technology-infrastructure-energy intersections and offers to connect for further collaborative ideas or projects.
- The article concludes by emphasizing the potential of public datasets for valuable discoveries and invites readers to engage in data-driven explorations.
- For more information or collaboration, the author can be reached at linkedin.com/in/dmitryabrown.
Read Full Article
14 Likes
For uninterrupted reading, download the app