A naukri.com initiative
Dev
1M
219
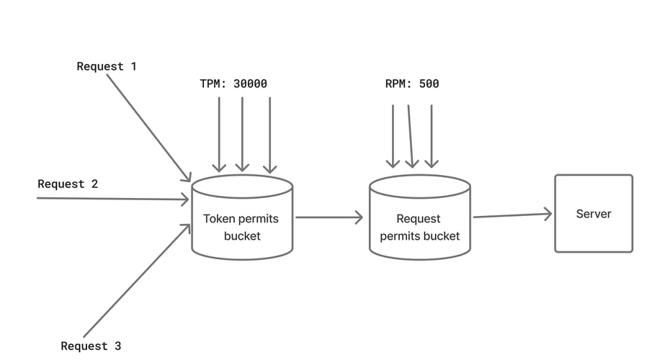
Image Credit: Dev
Handling rate limits of OpenAI models in Java using Guava, JTokkit
- Handling rate limited APIs optimally is crucial for faster execution of parallel requests, and OpenAI imposes request rate limit and token rate limit.
- Exponential Backoff is used to handle failed requests by retrying after increasing time intervals to prevent continuous retries.
- The Token Bucket Algorithm controls requests by allowing them only if enough tokens are available in a bucket that fills at a constant rate.
- Tokenizing the input and estimating output tokens are essential steps before sending requests to the OpenAI Responses API.
- Guava's RateLimiter class is used to manage token and request rate limits efficiently in Java applications.
- Backoff strategies are employed to handle situations where rate limits are not met, and requests need to be retried after a delay.
- The article presents code examples using the openai-java, JTokkit, and Guava libraries for implementing rate limit handling in Java applications.
- Dependencies for these libraries can be added through Maven, and the code example provided in the article can be used for simulation.
- The article also suggests resources for further reading on OpenAI rate limits, libraries used, and the Token Bucket Algorithm.
- Readers can explore different scenarios like changing request limits, token limits, and retry mechanisms for practical understanding.
Read Full Article
13 Likes
For uninterrupted reading, download the app