A naukri.com initiative
Medium
1M
231
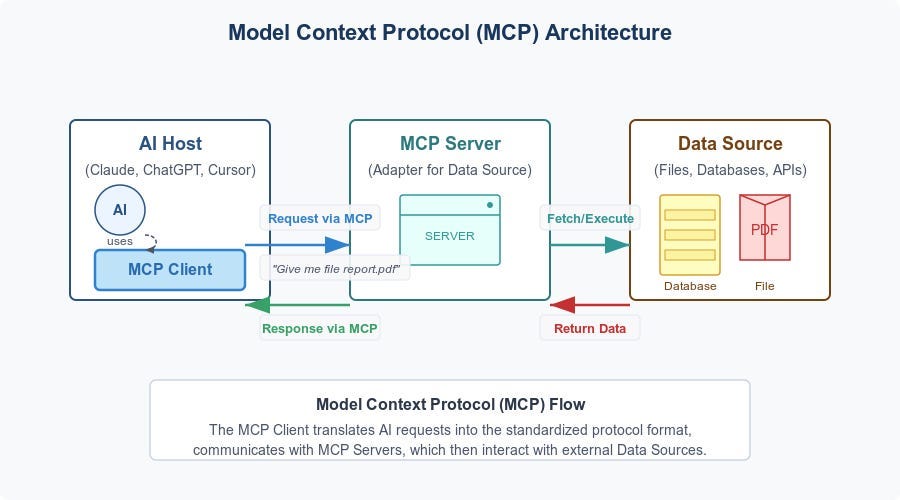
Image Credit: Medium
How MCP Works: Transforming the Future of Large Language Models
- MCP stands for Mixture of Compressed Experts, a concept that enhances the Mixture of Experts (MoE) model by incorporating compression techniques to address memory requirements.
- Traditional MoE models involve a set of expert sub-models, with only a few experts activated per input to improve computation efficiency. However, an increase in the number of experts leads to larger model sizes and higher memory usage.
- MCP overcomes this challenge by using compressed, lightweight experts that maintain a significant portion of the original capacity, promoting memory efficiency.
- MCP signifies a new approach for large language models, emphasizing efficiency, accessibility, and scalability to ensure sustainable and usable AI performance in real-world applications.
Read Full Article
13 Likes
For uninterrupted reading, download the app