A naukri.com initiative
Medium
2w
121
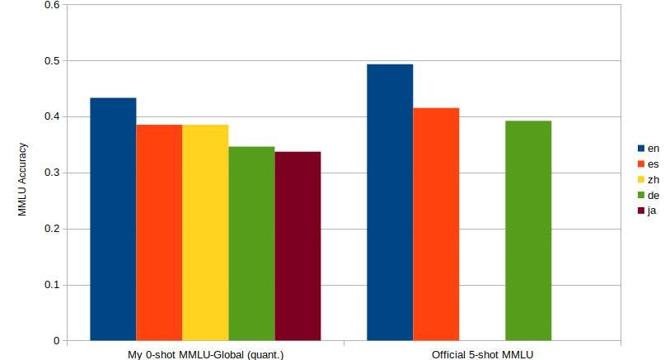
Image Credit: Medium
How to Evaluate Multilingual LLMs With Global-MMLU
- LLMs are typically evaluated against a large number of benchmarks, most of which are in English only.
- For multilingual models, it is rare to find evaluation metrics for every specific language in the training data.
- In this article, the author suggests using the Global-MMLU dataset for evaluating multilingual LLMs.
- The Global-MMLU dataset allows for evaluation using the MMLU benchmark in the language of choice.
Read Full Article
7 Likes
For uninterrupted reading, download the app