A naukri.com initiative
Medium
4w
440
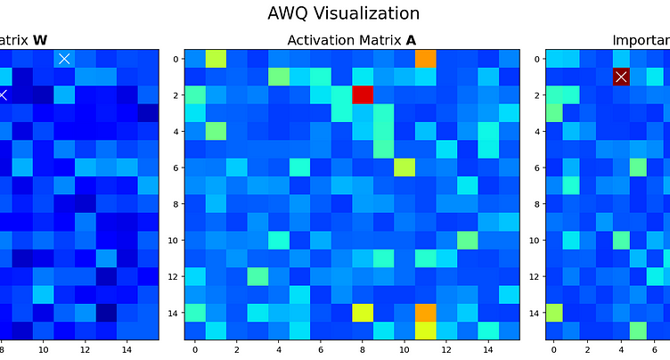
Image Credit: Medium
How to Use AWQ to Quantize LLMs
- Quantization is a method used to enable the use of large language models (LLMs) on limited hardware by reducing the number of bits per parameter.
- Most LLMs currently utilize 16-bit floating point formats, but using 4-bit quantization can lead to up to a 4x reduction in model size.
- Quantization algorithms are designed to minimize model size while maintaining performance.
- This article delves into the Activation-Aware Weight Quantization (AWQ) algorithm and its application to a small local LLM in a practical scenario.
- Quantization involves reducing the number of bits required to represent variables, resulting in smaller data storage.
- An example demonstrates the process of converting a 16-bit floating-point number to a 4-bit representation through a scaling factor.
Read Full Article
26 Likes
For uninterrupted reading, download the app