A naukri.com initiative
Medium
1M
215
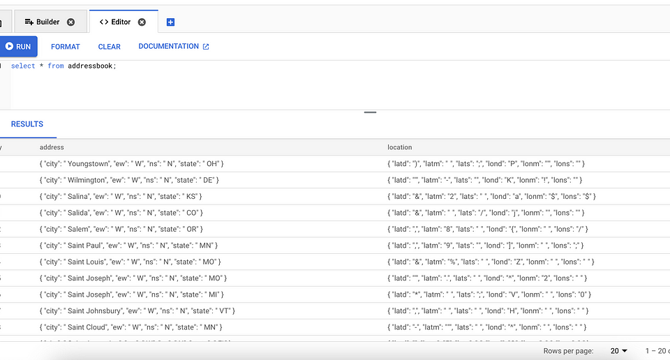
Image Credit: Medium
Load data from GCS to BigTable with GCP Dataproc Serverless
- The challenge lies in mapping Spark structured dataframes to BigTable column families.
- Traditionally, Bigtable provided client libraries for preparing rows for ingestion into BigTable, but they are verbose and challenging to maintain.
- To address this, a Spark BigTable connector was used with the GCStoBigTable dataproc template.
- The configuration includes specifying input files, file format, project ID, and catalog location.
Read Full Article
12 Likes
For uninterrupted reading, download the app