A naukri.com initiative
Feedspot
2w
189
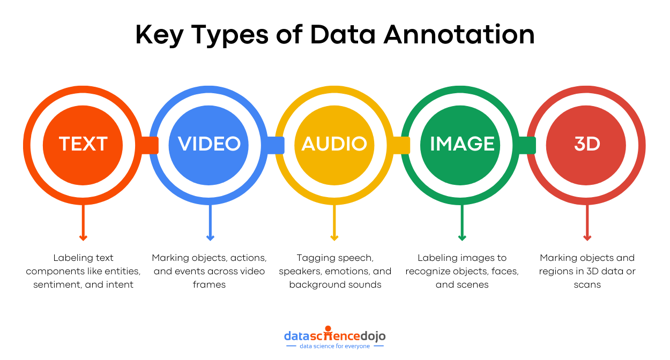
Image Credit: Feedspot
Master Data Annotation in LLMs: A Key to Smarter and Powerful AI!
- Language Models (LLMs) are a vital technology in the AI landscape, trained on vast datasets and advanced algorithms.
- Data annotation is crucial for LLMs to ensure accuracy and relevance in the data used for training.
- Text annotation categorizes elements in text like named entities, parts of speech, sentiment, etc., aiding in language processing tasks.
- Audio annotation involves tagging speech segments, emotions, and background sounds for tasks like speech recognition.
- Video annotation labels objects, actions, and events in video frames for visual information interpretation by models.
- Image annotation helps AI systems recognize objects, faces, and scenes for applications like autonomous driving and object detection.
- 3D data annotation is crucial for AR, VR, autonomous systems, marking objects in 3D space for effective navigation.
- Data annotation aids in LLMs' accuracy, understanding of language nuances, and task-specific responses.
- Annotated data enhances user conversations with LLMs, providing context-specific and accurate responses.
- RLHF with annotated feedback refines LLMs' behavior, aligning model responses with user expectations for better performance.
Read Full Article
11 Likes
For uninterrupted reading, download the app