A naukri.com initiative
Feedspot
1M
107
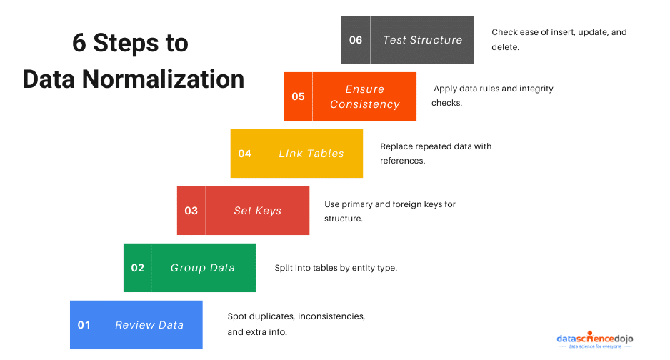
Image Credit: Feedspot
Mastering Data Normalization: A Comprehensive Guide
- Data normalization involves organizing data to reduce redundancy and improve efficiency, ensuring clean, accurate datasets.
- Normalization is crucial for relational databases, maintaining structured connections between data.
- It enhances data integrity, scalability, and system performance, making it a foundational aspect of data-driven projects.
- Normalization safeguards against redundancy and anomalies, facilitating accurate, efficient, and scalable databases.
- It categorizes data into meaningful groups, simplifying management, updates, and integration with applications.
- Normal forms like 1NF, 2NF, 3NF, and BCNF progressively optimize databases by removing redundancies and dependencies.
- Testing data structures post-normalization ensures easy addition, updating, and deletion of records.
- Data normalization isn't limited to databases, also benefiting data warehousing, analytics, and machine learning by ensuring accurate, structured data.
- Denormalization balances data redundancy with performance, speeding up data retrieval in read-heavy applications.
- Knowing when to normalize for consistency and when to denormalize for speed is key to efficient database design.
Read Full Article
6 Likes
For uninterrupted reading, download the app