A naukri.com initiative
Semiengineering
1M
375
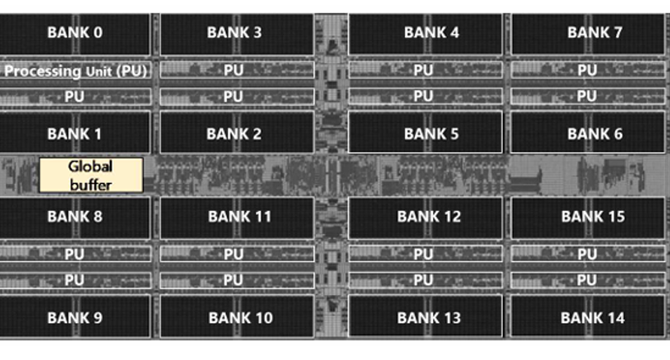
Image Credit: Semiengineering
Memory Wall Problem Grows With LLMs
- The imbalance between data processing needs for training large language models and the slow data movement between memories and processors has sparked a global search for better solutions.
- The forecasted growth of the GPU market to $190 billion by 2029 highlights the importance of scalable matrix multiplication engines like GPUs for AI training.
- Training large language models (LLMs) involves significant matrix multiplications and demands immense computing resources and memory.
- Energy efficiency concerns arise due to the high computational and memory requirements of LLMs, impacting data centers and overall power consumption.
- New research focuses on architectures, algorithms, and computational approaches to address the challenges posed by LLMs.
- Different memory architectures and technologies, such as NOR flash, are being explored to optimize performance and energy efficiency for various tasks.
- Computation-in-memory approaches, like near-memory architectures and the use of emerging memory technologies, aim to reduce data movement and improve processing efficiency.
- Inference tasks on the edge require balancing performance, bandwidth, and power consumption, especially for portable and wearable devices.
- Despite advancements in hardware, overcoming the memory wall and catering to the growing demands of machine learning models may require innovations in algorithms.
- The quest for better algorithms, in addition to advancements in silicon, is crucial for addressing the challenges posed by large language models.
Read Full Article
22 Likes
For uninterrupted reading, download the app