A naukri.com initiative
Medium
1M
27
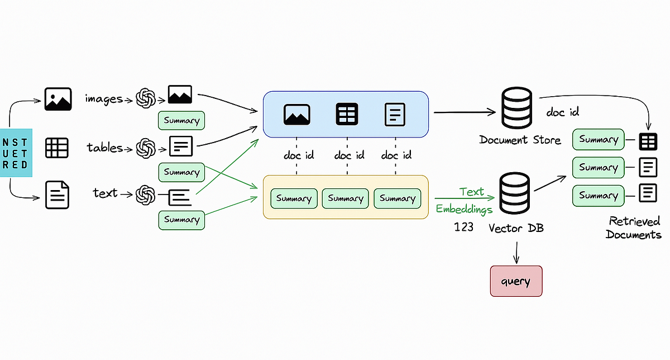
Image Credit: Medium
Multimodal RAG From PDFs To Data Store For PDF Chatbots Part-2: Summarization
- This article is the second part of a series on creating a Multimodal RAG (Retrieve, Aggregate, Generate) pipeline for chatbots from PDFs. The first part focused on extracting text, tables, and images from PDFs.
- In this second part, the author discusses the process of summarizing the extracted data elements using text embeddings and storing them in a vector database.
- The article outlines the flow of the process, starting with the creation of a standard prompt for the language model. The author also provides instructions for creating a prompt for image elements.
- The article also mentions the use of the Gemini-2.0-flash model for cost-effectiveness. The importance of a .env file for storing the Google AI API key is highlighted.
Read Full Article
1 Like
For uninterrupted reading, download the app