A naukri.com initiative
Dev
1w
230
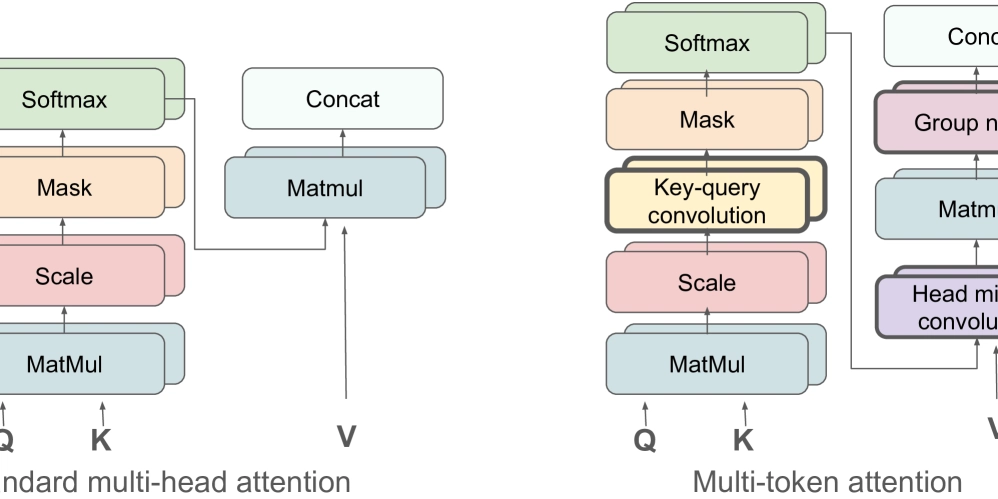
Image Credit: Dev
New AI Breakthrough Makes Language Models 15% Faster and More Accurate with Multi-Token Processing
- New AI breakthrough makes language models 15% faster and more accurate with multi-token processing.
- Multi-Token Attention improves transformer models by processing multiple tokens together.
- Introduces key-query convolution that allows attention heads to look at token context.
- Achieves 15% faster processing with improved perplexity on language tasks. Particularly effective for summarization, question answering, and long-context tasks.
Read Full Article
13 Likes
For uninterrupted reading, download the app