A naukri.com initiative
Medium
2w
342
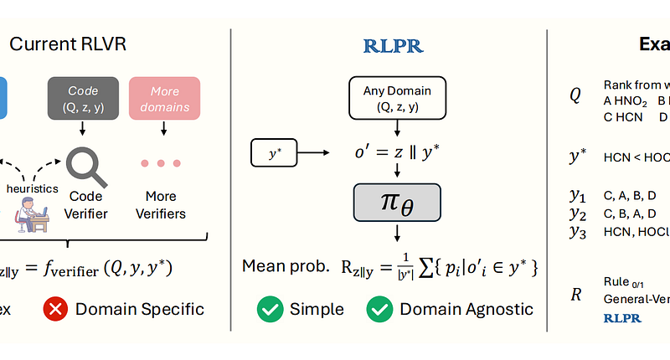
Image Credit: Medium
No Verifier? No Problem: Reinforcement Learning with Reference Probabilities
- RLPR (Reinforcement Learning with Reference Probability Reward) is proposed to address the limitation of RLVR in general domains without verifiers.
- RLVR is often restricted to math and code tasks due to the reliance on domain-specific verifiers for rewards.
- RLPR uses the model's own probability of generating a reference answer as a reward signal, eliminating the need for external verifiers.
- This self-rewarding setup alleviates manual reward engineering and enhances scalability across different domains.
- The authors present two main technical contributions in the RLPR framework.
- Experiments conducted on 7 benchmarks and 3 model families (Qwen, Llama, Gemma) demonstrate that RLPR improves general reasoning and outperforms verifier-free baselines and even specialized verifier methods like LLMs.
- The code for RLPR has been made publicly available.
Read Full Article
20 Likes
For uninterrupted reading, download the app