A naukri.com initiative
Hackernoon
1w
247
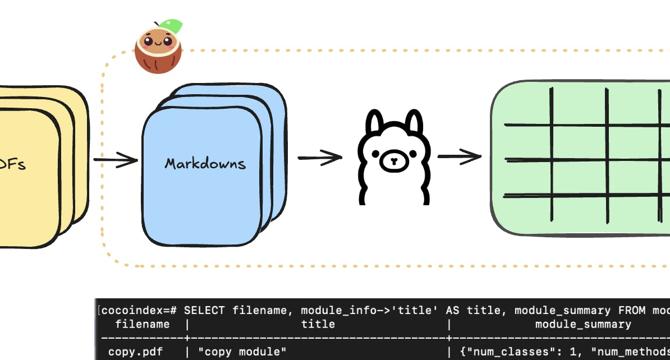
Image Credit: Hackernoon
On-premise structured extraction with LLM using Ollama
- The blog discusses using Ollama for on-premise structured data extraction, runnable locally or on a server.
- Installation involves downloading and installing Ollama and pulling LLM models using commands like 'ollama pull llama3.2'.
- Structured data extraction from Python Manuals includes defining output data classes for ModuleInfo, ClassInfo, MethodInfo, and ArgInfo.
- The CocoIndex flow for extracting data from markdown files is outlined using functions like ExtractByLlm.
- After extraction, data can be cherrypicked using the collector function and exported to a table like 'modules_info'.
- Querying the index involves commands like 'python main.py cocoindex update' and querying the table in a Postgres shell.
- CocoInsight, a tool for understanding data pipelines, is mentioned with a dashboard showing defined flows and collected data.
- Adding a summary to the data involves defining a ModuleSummary structure and a function to summarize the data, integrated into the flow.
- For PDF file extraction, a custom function like PdfToMarkdown is discussed to convert PDF files to markdown format for input.
- The necessity of defining a spec and executor for PdfToMarkdown is highlighted due to preparation work requirements before processing real data.
Read Full Article
14 Likes
For uninterrupted reading, download the app