A naukri.com initiative
Medium
3w
383
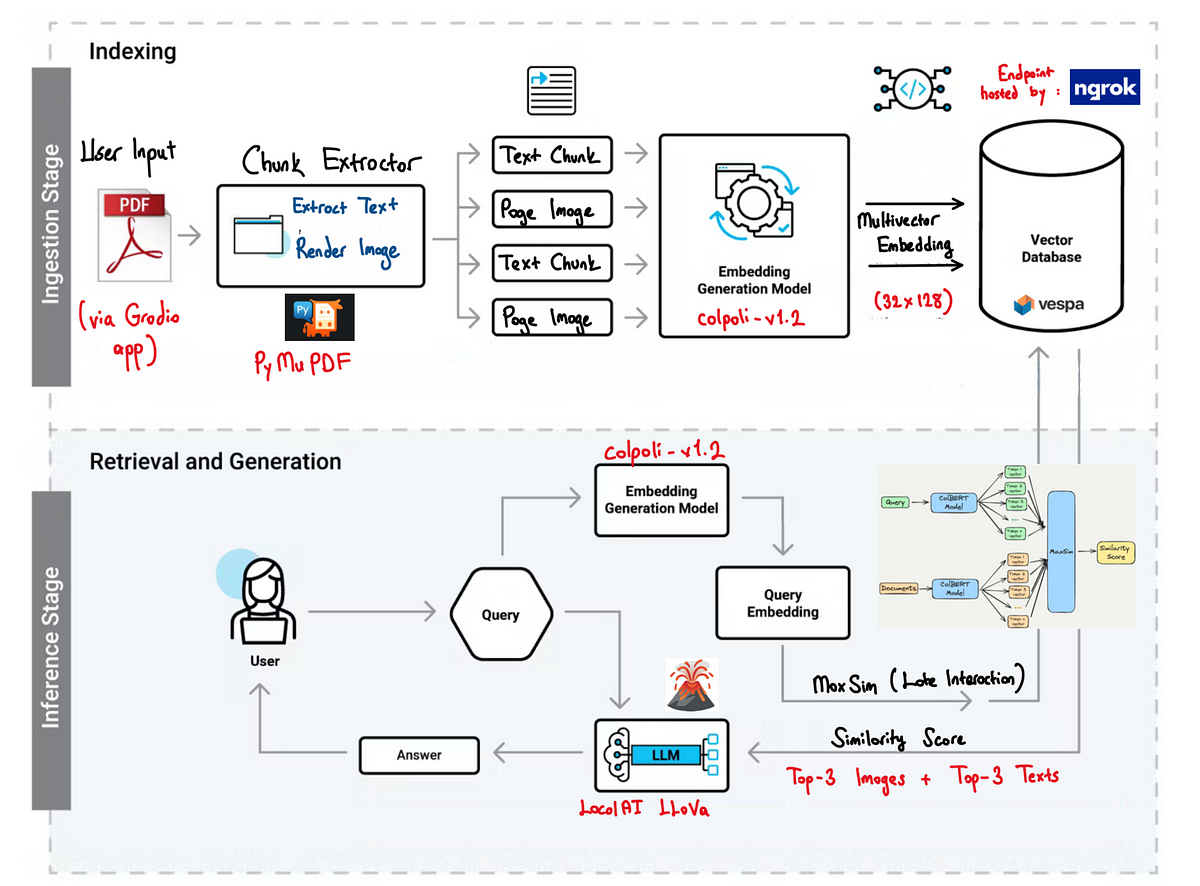
Image Credit: Medium
Reimagining Multimodal Retrieval with ColPali: A New Paradigm in RAG Pipelines
- ColPali is a new vision-language model that embeds and retrieves multimodal content in a shared latent space, offering a more advanced RAG pipeline design.
- Traditional retrieval systems often struggle with multimodal content, leading to noise and misalignment when incorporating images.
- ColPali is a dual-encoder model that embeds both text and image inputs into the same vector space, enabling modality-agnostic retrieval.
- The system uses MaxSim similarity for more accurate matching between queries and stored vectors, allowing for semantic relevance extraction regardless of modality.
- An interactive Gradio interface showcases the system, providing users with quick and relevant results from uploaded PDFs based on natural language queries.
- The approach reduces cognitive load by presenting users with instant, relevant information from both text and images in documents.
- LLaVA, a local vision-language model, is used to generate meaningful answers offline, ensuring responses are based strictly on retrieved evidence.
- By leveraging joint embedding space, multivector storage, and local generation, ColPali offers a modality-agnostic and privacy-respecting retrieval system.
- The article provides source code for the pipeline on GitHub for those interested in implementing similar multimodal retrieval solutions.
Read Full Article
23 Likes
For uninterrupted reading, download the app