A naukri.com initiative
Hackernoon
7d
183
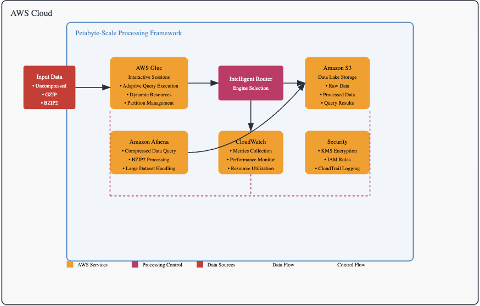
Image Credit: Hackernoon
Revolutionizing Petabyte-Scale Data Processing on AWS: Advanced Framework Unveiled
- This article presents an advanced framework for processing petabyte-scale datasets using AWS Glue Interactive Sessions, custom libraries, and Amazon Athena.
- The framework addresses significant challenges in scalability, cost-efficiency, and performance for massive data volumes.
- The proposed data processing framework integrates AWS Glue Interactive Sessions as the primary processing engine, with Amazon Athena utilized for specific compression scenarios.
- Intelligent Processing Selection: A standout feature of the framework is its ability to select the most appropriate processing engine based on the characteristics of the dataset, such as compression type and size.
- Monitoring and Observability: Effective monitoring is essential for maintaining high performance and quickly identifying any issues during processing.
- Implementation of the proposed framework has demonstrated significant benefits: Cost reduction: Up to 60% reduction in processing costs through intelligent selection of the processing engine and dynamic resource allocation.
- Performance Improvement: Approximately 40% improvement in processing times for compressed datasets, particularly when using Amazon Athena for suitable scenarios.
- Scalability: The framework efficiently handles petabyte-scale datasets, providing near real time processing capabilities.
- The framework’s intelligent processing selection ensures that datasets are processed using the most efficient engine based on their characteristics.
- This paper presents a robust and cost-effective solution for processing petabyte scale data by combining AWS Glue Interactive sessions, custom libraries, and Amazon Athena.
Read Full Article
11 Likes
For uninterrupted reading, download the app