A naukri.com initiative
Hackernoon
2w
296
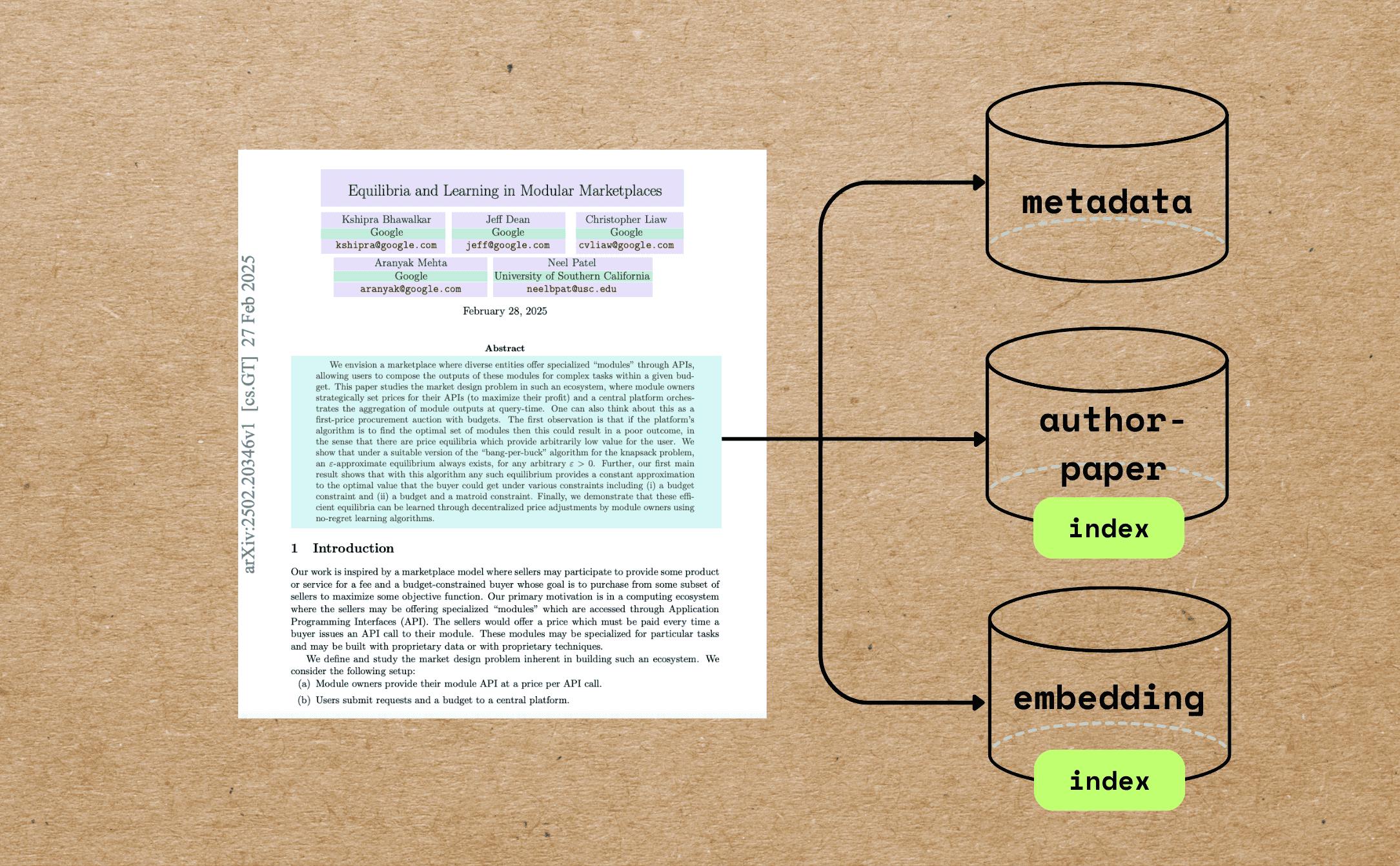
Image Credit: Hackernoon
Turn Your PDF Library into a Searchable Research Database with 100 Lines of Code
- Learn how to utilize 100 lines of code to turn your PDF library into a searchable research database.
- Extract metadata like title, author info, and abstract, and build semantic embeddings.
- Enable better metadata-driven semantic search results and create author-to-paper mappings.
- The tutorial covers PDF preprocessing, metadata extraction, relational data collection, and semantic embedding.
Read Full Article
17 Likes
For uninterrupted reading, download the app