A naukri.com initiative
Hackernoon
1M
77
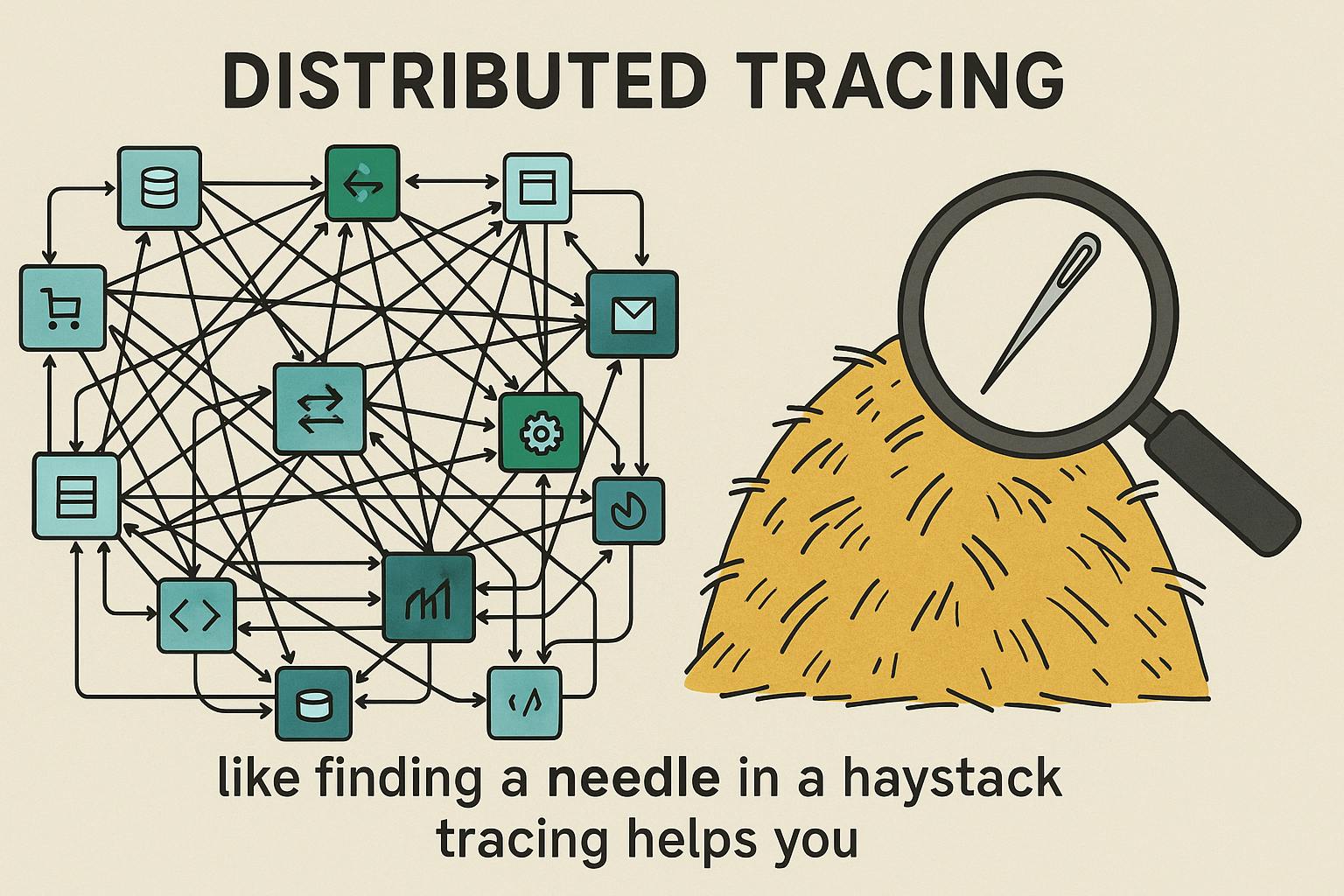
Image Credit: Hackernoon
When It's 3AM and Your App is on Fire: How Distributed Tracing Saves the Day
- Distributed tracing is crucial for tracking performance issues in complex microservices architectures.
- Without distributed tracing, troubleshooting involves manual correlation of timestamps and guesswork.
- With distributed tracing, one can easily identify latency issues and pinpoint problematic components.
- The three pillars of observability are logs, metrics, and traces, each serving a different purpose.
- Distributed tracing provides end-to-end visibility of request flows, aiding in detecting failures and performance bottlenecks.
- Real-world examples include Shopify using tracing to resolve Black Friday issues and Uber identifying timeouts through tracing.
- Metrics signal when something is wrong, logs offer detailed context, and traces reveal the 'why' and 'where' of issues.
- Starting with an observability framework like OpenTelemetry or Jaeger and instrumenting code is vital for distributed tracing.
- Effective data collection, meaningful tags, and scaling the tracing implementation are key steps in maximizing its benefits.
- Common pitfalls to avoid include excessive data collection, poor sampling, and siloed analysis.
- The future of distributed tracing includes AI-powered anomaly detection, enhanced privacy controls, and business-centric observability.
Read Full Article
4 Likes
For uninterrupted reading, download the app