A naukri.com initiative
Medium
1M
153
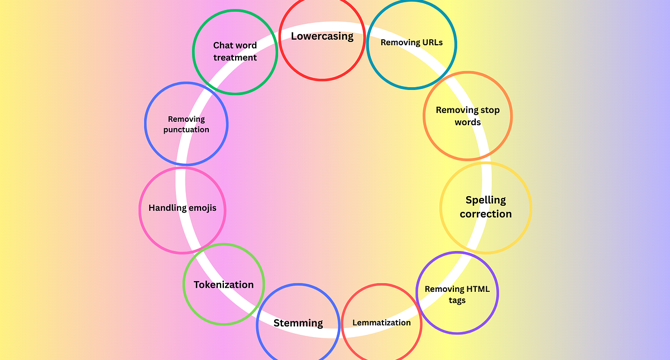
Image Credit: Medium
Why Most NLP Projects Fail: A Beginner’s Guide to Text Preprocessing
- Text preprocessing is a crucial step in NLP projects to ensure model performance.
- Lowercasing text helps maintain consistency and reduce vocabulary size.
- Removing HTML tags, URLs, punctuation, and informal words enhances data quality.
- Spell correction tools like TextBlob are used to rectify common mistakes.
- Removing stop words can assist in improving processing speed and reducing tokens.
- Handling emojis based on task requirements can influence sentiment analysis results.
- Tokenization is essential to split text accurately for model understanding.
- Methods like split(), regex, and libraries like NLTK and SpaCy are used for tokenization.
- Stemming helps reduce words to their root form, useful for information retrieval systems.
- Porter Stemmer and Snowball Stemmer from NLTK are commonly used for stemming.
- Lemmatization ensures proper reduction of inflected words to their base form using WordNet.
Read Full Article
9 Likes
For uninterrupted reading, download the app