A naukri.com initiative
Medium
7h
59
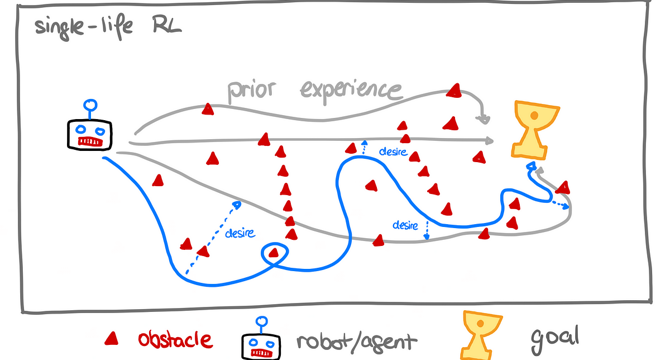
Image Credit: Medium
You Only Live Once: How does Single-Life Reinforcement Learning work?
- Single-life Reinforcement Learning (SLRL) aims to train robots with sub-optimal prior knowledge so that the training process more closely mirrors real-life conditions. This means if the robot is only given a single chance to complete a task, SLRL must enable it to backtrack when it gets stuck. SLRL rewards the robot for particular actions taken during the task, such as moving toward areas where there are cries for help or by opening doors. The Q-weighted adversarial learning algorithm (QWALE) which guides the robot to consistently move closer to the pathways that lead to task completion, performed better in 4 RL challenges than previous distribution matching methods.
- SLRL is based on concepts used in Reinforcement Learning (RL), where a robot makes decisions to achieve specific goals. Usually, RL resets the environment so that the robot can repeatedly learn, but SLRL needs to adapt to real-life scenarios where there is only one chance to complete a task. If the robot gets stuck, it must be able to backtrack and navigate unknown terrain. SLRL employs the Q-function, policy, state-action, reward, and entropy concepts to enable the robot to find its way to complete tasks with minimal backtracking.
- The researchers equipped the robot with sub-optimal prior knowledge to train it in disaster relief scenarios so it can rescue people from burning buildings. The robot also has a discriminator for evaluating the distance between the prior knowledge and the current state when navigating new environments. QWALE incentivizes the robot to move closer to the pathways that lead to task completion, which assists in recovery when mistakes or trapped situations occur.
- QWALE needs to be agnostic to the quality of prior experiences to help robots tackle more challenging and unknown terrains. The more similar the task or state, the quicker robots can complete a task. The researchers found that QWALE outperformed other algorithms, achieving the best results in four different RL challenges - such as arranging items on a table and using tools to achieve complex tasks in a kitchen environment.
- The study found that standard fine-tuning using RL methods doesn't account for mistakes or trapped situations, and prior data significantly improves backtracking and recovery. QWALE required 20 to 40% fewer steps on average compared to other methods, demonstrating how efficient and effective SLRL can be in evaluating prior knowledge. Future models using SLRL could enable sophisticated robots to handle new environments more effectively.
Read Full Article
3 Likes
For uninterrupted reading, download the app