A naukri.com initiative
Medium
7h
91
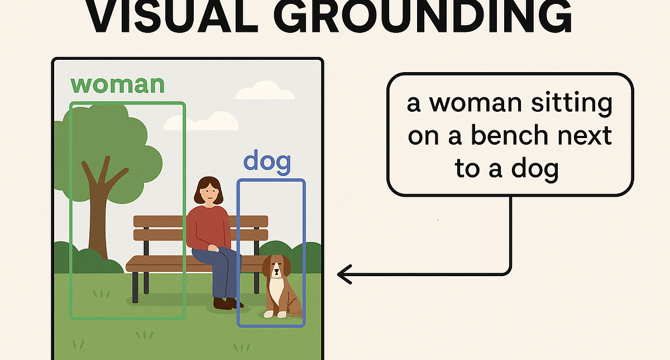
Image Credit: Medium
️ What Is Visual Grounding? The AI Tech That Sees and Understands What You Say
- Visual grounding is an emerging field in artificial intelligence that enables machines to understand and act on visual and linguistic cues.
- It involves connecting words or phrases to specific regions in an image or video, allowing AI systems to recognize objects and interpret contextual references accurately.
- Recent advancements like GeoGround, SimVG, HiVG, and LynX have pushed the boundaries of visual grounding, improving performance, data generation, and multimodal learning.
- This technology has the potential to revolutionize areas such as autonomous systems and intelligent agents.
Read Full Article
5 Likes
For uninterrupted reading, download the app