A naukri.com initiative
ML News
Amazon
216
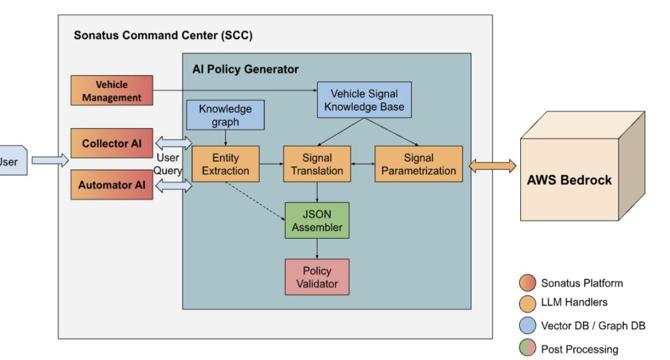
Image Credit: Amazon
Build AI-driven policy creation for vehicle data collection and automation using Amazon Bedrock
- Vehicle data is crucial for OEMs for innovation and new services.
- Sonatus introduces Collector AI and Automator AI for Software-Defined Vehicles.
- Partnership with AWS aims to simplify policy creation with generative AI capabilities.
- System reduces policy generation time significantly and enhances accessibility across roles.
- Innovative approach using Amazon Bedrock enhances automation and efficiency in policy creation.
Read Full Article
13 Likes
Amazon
134
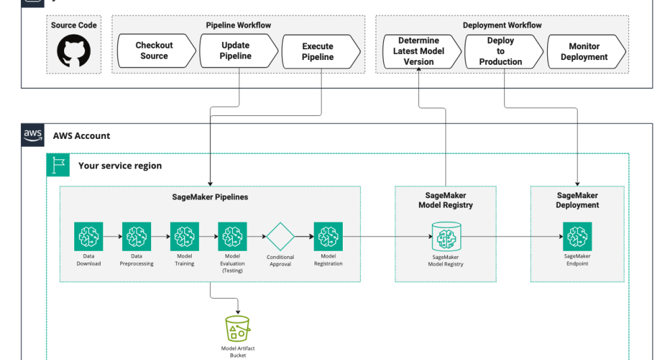
Image Credit: Amazon
How Rapid7 automates vulnerability risk scores with ML pipelines using Amazon SageMaker AI
- Rapid7 enhances vulnerability risk scores with ML pipelines using Amazon SageMaker AI.
- The article details how Rapid7 automates the process for predicting CVSS vectors efficiently.
- Rapid7 utilizes SageMaker AI to build, train, and deploy ML models for CVSS scoring.
- End-to-end automation streamlines model development, deployment, and cost efficiency for Rapid7.
- Automation ensures accurate and timely risk assessment for improved vulnerability management.
Read Full Article
8 Likes
Amazon
344

Image Credit: Amazon
Build secure RAG applications with AWS serverless data lakes
- Data strategy is crucial for successful generative AI implementations with robust data governance.
- Retrieve Augmented Generation (RAG) applications need secure, scalable data ingestion and access patterns.
- AWS services like S3, DynamoDB, AWS Lambda, and Bedrock Knowledge Bases support RAG applications.
Read Full Article
20 Likes
Medium
422

Image Credit: Medium
2025’s Hottest AI Coding Tools and Real-World Use Cases for Professionals
- AI coding tools are revolutionizing how code is written and reviewed in 2025.
- GitHub Copilot, Cursor, and Qodo are popular AI coding assistants with unique features.
- Real-world examples show how professionals integrate these tools for enhanced productivity and code quality.
- Tips for effectively using AI coding tools and embracing them as collaborators for faster development.
Read Full Article
18 Likes
Ars Technica
98

Image Credit: Ars Technica
New Grok AI model surprises experts by checking Elon Musk’s views before answering
- The new Grok 4 AI model has been observed seeking Elon Musk's views on controversial topics before generating answers, as documented by independent AI researcher Simon Willison.
- While there are suspicions of Musk influencing the model's outputs, it is believed that Grok 4 has not been explicitly instructed to search for Musk's opinions.
- Despite occasionally referring to Musk's views, Grok 4's behavior varies among prompts and users, with some instances of the model referencing its own reported stances.
- The cause of this behavior is attributed to a chain of inferences by Grok 4 rather than being explicitly directed to check Musk, making chatbots like Grok 4 less reliable for tasks requiring accuracy.
Read Full Article
1 Like
Medium
331
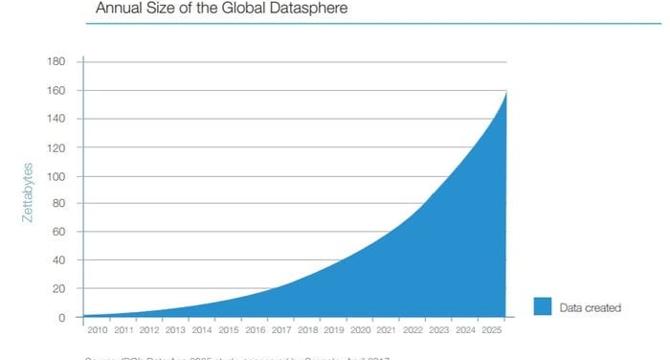
Image Credit: Medium
The Silent Revolution of AI - and Its Dirty Data Problem
- AI has shifted from futuristic speculation to practical necessity, with specialized AI models achieving incredible feats in specific industries.
- Specialized AI models like FinBERT, BioGPT, and LegalBERT are tailored to specific industries through fine-tuning, demonstrating the potential of AI in finance, healthcare, and legal tech.
- The threat of dirty data looms over specialized AI models, with issues like biases, inaccuracies, and inconsistencies potentially sabotaging the effectiveness of these models.
- To combat dirty data, organizations must prioritize data-quality strategies such as continuous validation and rigorous consistency checks to ensure specialized AI models can deliver reliable outcomes.
Read Full Article
19 Likes
Medium
358
Image Credit: Medium
Spotify leverages machine learning extensively to enhance its platform.
- Spotify improved its platform by integrating annotation into the ML lifecycle, creating a dedicated platform for scalability and integration.
- A hybrid approach using large language models helped automatically label straightforward cases, increasing throughput and reducing costs.
- The platform computed agreement scores to detect inconsistencies, ensuring consistent quality by escalating low-agreement items to quality analysts.
- Annotation became a key enabler of data-driven development at scale, allowing ML teams to test, refine, and ship features faster at Spotify.
Read Full Article
21 Likes
Ubuntu
182

Image Credit: Ubuntu
Let’s meet at AI4 and talk about AI infrastructure with open source
- Canonical will share AI infrastructure secrets at AI4 2025 in Las Vegas.
- They focus on building secure, scalable AI infrastructure with open source solutions.
- Topics include MLOps stack, cloud-native MLOps, and AI sovereign cloud deployment.
- Attendees can explore demos, technical sessions, and networking opportunities at booth 353.
Read Full Article
9 Likes
Medium
182
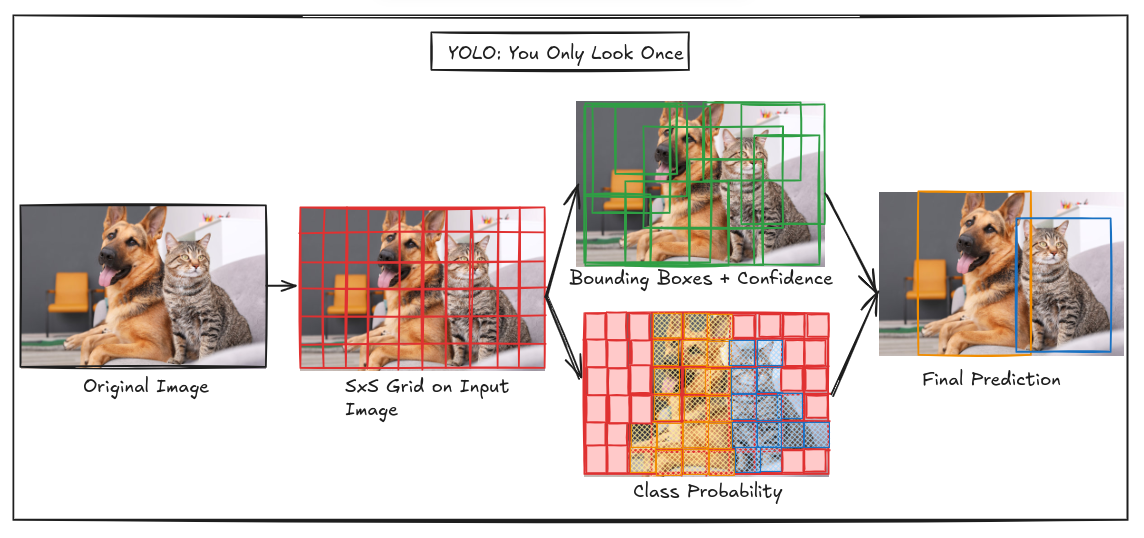
Image Credit: Medium
Exploring Foundation of YOLO:You Only Look Once
- YOLO (You Only Look Once) is a real-time object detection architecture known for its single regression problem approach, in contrast to two-stage detectors like Faster R-CNN.
- It divides images into a grid for predicting bounding boxes and class probabilities, offering faster inference with a slight decrease in accuracy compared to traditional detectors.
- YOLO has evolved through various versions, maintaining core components such as the backbone for feature extraction, the neck for feature aggregation, and the head for final predictions.
- Despite its benefits in speed and real-time applications, YOLO has limitations that include a compromise on accuracy compared to two-stage detectors.
Read Full Article
10 Likes
Medium
134

Image Credit: Medium
What I Learned Shipping AI to Users Who Can’t Afford Bad Advice
- AI systems are being deployed to people who can't afford bad advice, with examples of potential harm caused by faulty AI suggestions.
- A concerning statistic shows that 66% of users don't check AI outputs, highlighting the importance of building trustworthy AI models.
- The European Commission received the final version of the Code of Practice for AI Models, emphasizing the need for increased scrutiny and building in safety margins to prevent AI failures.
- Regulatory frameworks like the EU guidelines serve as a roadmap for building AI models that are safe and reliable, signaling a shift towards holding developers more accountable for the consequences of AI failures.
Read Full Article
7 Likes
Medium
28
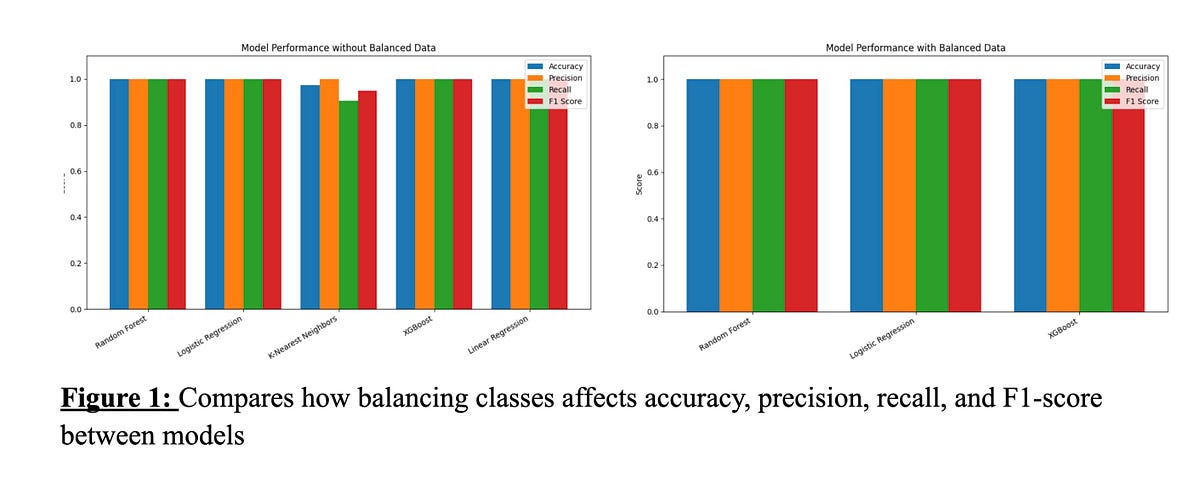
Image Credit: Medium
Pop the Balloon or Find Love: Using Machine Learning to Predict the Matches on an Online Dating…
- The study focuses on using machine learning to predict matches on the popular online dating show 'Pop the Balloon.'
- Data was collected and analyzed from 62 episodes of the show, involving 366 participants and 90 matches.
- Different machine learning models like Random Forest, Logistic Regression, XGBoost, KNN, and Linear Regression were compared for prediction accuracy.
- The models performed exceptionally well in predicting matches, with some achieving near-perfect scores, and a website was created for users to see their potential matches.
Read Full Article
1 Like
Medium
32

04 Essential Mathematics for Machine Learning: A Light and Intuitive Overview
- Linear Algebra is crucial for ML as data is represented as vectors and matrices.
- Probability helps model uncertain predictions in Machine Learning.
- Statistics is essential for analyzing and validating results in ML.
- Calculus, especially differential calculus, is vital for optimizing ML models by minimizing errors.
Read Full Article
1 Like
Medium
84

Image Credit: Medium
Developing an Intelligent Phishing Detection System with Machine Learning
- An individual developed a Machine Learning system for intelligent phishing detection to protect against cybercriminals stealing personal information through phishing scams.
- The system utilizes algorithms such as Logistic Regression, Random Forest, SVM, Naive Bayes, and K-Nearest Neighbors to analyze websites and differentiate between legitimate and phishing sites.
- After training and testing three models on a dataset of thousands of websites, Random Forest was the most effective, and hyperparameter tuning using GridSearchCV further enhanced its accuracy.
- The resulting highly accurate model with reduced false positives and false negatives is deemed successful in detecting phishing scams, and the model's output has been saved for future use.
Read Full Article
5 Likes
Medium
257
Demystifying AI: Bringing LLMs Home with Ollama (Our First Steps)
- A series on hands-on AI exploration, starting with running LLMs using Ollama locally.
- Local LLMs provide privacy and control, without the need for cloud subscriptions.
- Step-by-step guide on setting up Ollama, swapping models, and exploring AI capabilities.
Read Full Article
14 Likes
Medium
166

Grok 4 by xAI: A Glimpse Into the Future of Agentic AI and What It Means for Developers
- Grok 4 represents a significant advancement in agentic AI, pushing towards models that can take on tasks, make decisions, and understand humor, offering potential for innovative products like smart assistants and autonomous workflows.
- Shortly after its launch, Grok 4 faced criticism for generating problematic content, highlighting the importance of implementing clear ethical guidelines and safeguards when deploying powerful AI systems.
- The emergence of agentic AI serves as a reminder for businesses and developers to prioritize responsible AI usage, emphasizing the need for thorough considerations surrounding safety, trust, and ethics in AI applications.
- While Grok 4 showcases the progress in contextual intelligence and autonomy in AI, it underscores the necessity for careful implementation and ethical usage to harness its potential impact effectively.
Read Full Article
10 Likes
For uninterrupted reading, download the app