A naukri.com initiative
Medium
1M
263
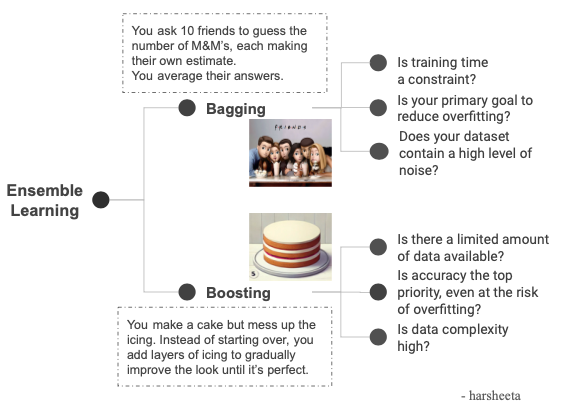
Image Credit: Medium
A Beginner’s Guide to Bagging and Boosting in Machine Learning with examples
- Bagging reduces unpredictability in a model's predictions and stabilizes predictions by creating multiple smaller models that vote on the final answer.
- Each model in Bagging leaves out some samples, known as out-of-bag samples, to calculate an unbiased estimate of model accuracy.
- Boosting builds models one at a time, focusing on fixing errors of the previous model, and aims to reduce bias and achieve high accuracy on complex data.
- Random Forest leverages Bagging by training multiple decision trees on different subsets of data and features, while Gradient Boosting improves accuracy by focusing on previous errors.
Read Full Article
15 Likes
For uninterrupted reading, download the app