A naukri.com initiative
Medium
2w
138
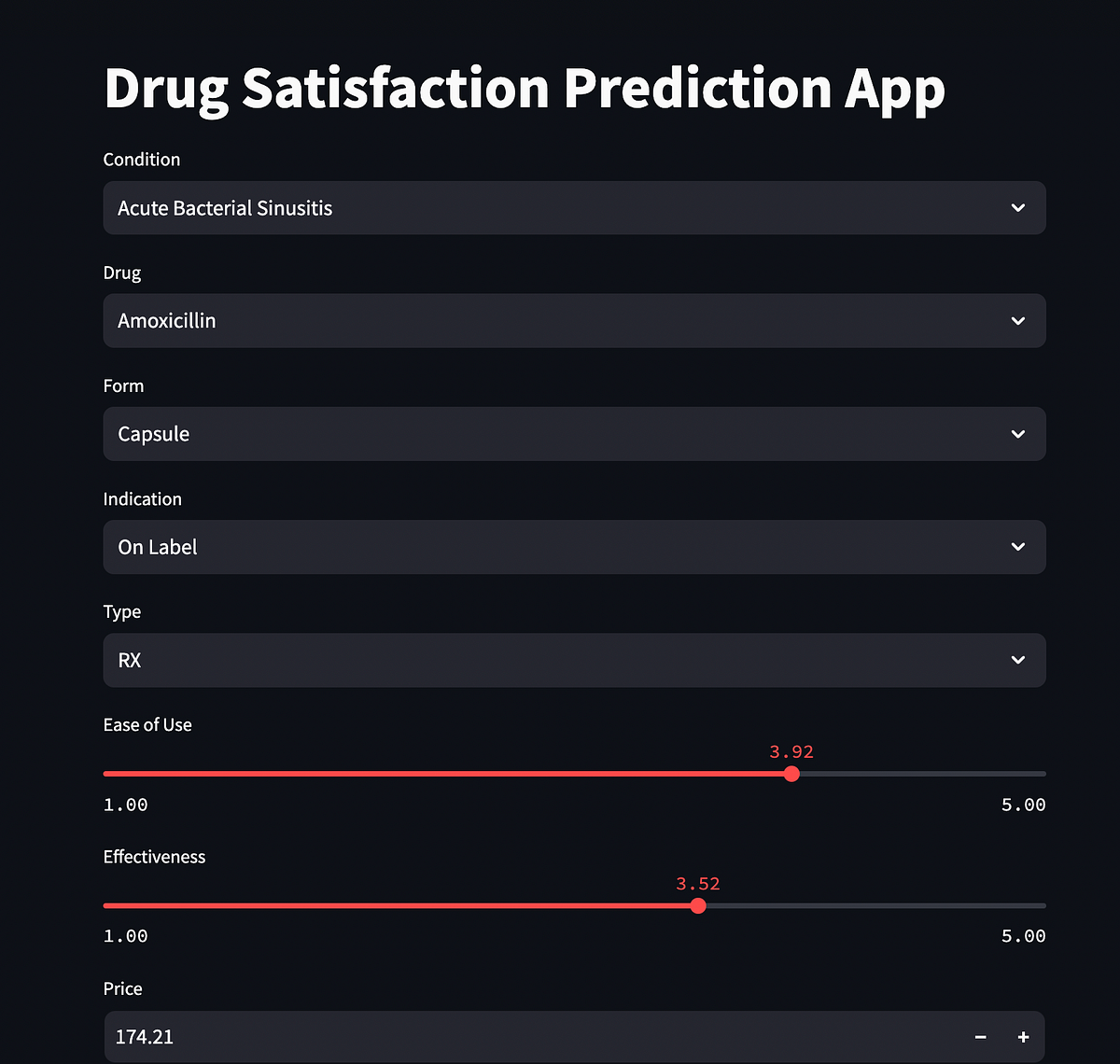
Image Credit: Medium
A Capstone Journey into Healthcare and Data Science
- The dataset used for this project was sourced from Kaggle, containing drug performance metrics for 37 common conditions.
- The data was loaded using pandas and explored to understand its structure and identify missing values.
- A pipeline was created to automate the training process, integrating the preprocessor and model.
- The Drug Satisfaction Prediction App demonstrates the integration of data science and healthcare, providing real-world solutions and opportunities for further advancements.
Read Full Article
8 Likes
For uninterrupted reading, download the app