A naukri.com initiative
Medium
2d
265
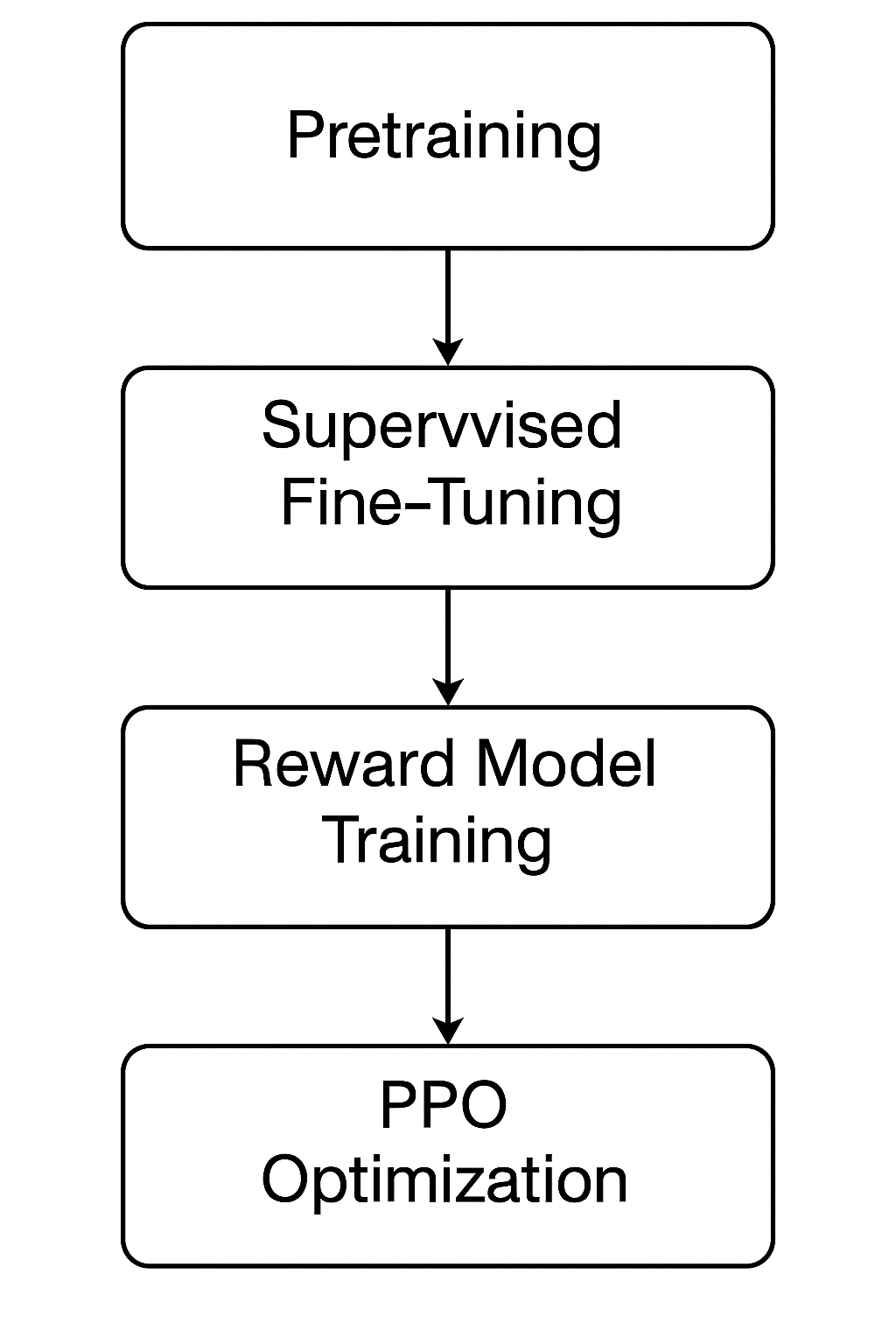
Image Credit: Medium
A Comprehensive Introduction to Reinforcement Learning from Human Feedback (RLHF)
- Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning large language models with human intent, seen in models like ChatGPT and Claude.
- RLHF uses human feedback to guide models towards desired behavior, moving beyond traditional supervised learning.
- RLHF involves a three-phase pipeline that enables models to iteratively improve based on human-preferred behavior.
- Through techniques like Proximal Policy Optimization (PPO), RLHF optimizes language models by generating responses aligned with human preferences.
Read Full Article
15 Likes
For uninterrupted reading, download the app