A naukri.com initiative
Medium
1w
323
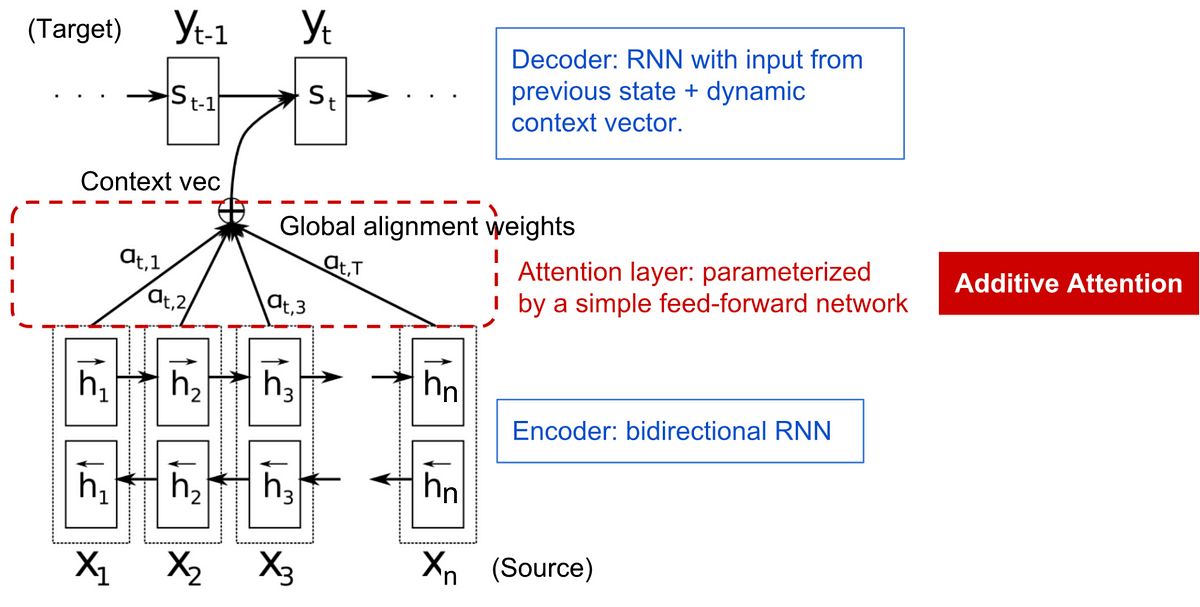
Image Credit: Medium
A Technical Overview of the Attention Mechanism in Deep Learning
- The basic attention mechanism is demonstrated with a scoring function to calculate weights and is widely used in various deep learning models.
- Self-attention forms the base of models like BERT and GPT, with applications in natural language processing tasks.
- Multi-head attention, including scaled dot-product attention and attention masking, finds applications in improving model performance and computational efficiency.
- Practitioners are advised to experiment with diverse datasets and hyperparameters to enhance model performance, leveraging tools like Hugging Face Transformers and frameworks like PyTorch for customization.
Read Full Article
19 Likes
For uninterrupted reading, download the app