A naukri.com initiative
Medium
1M
45
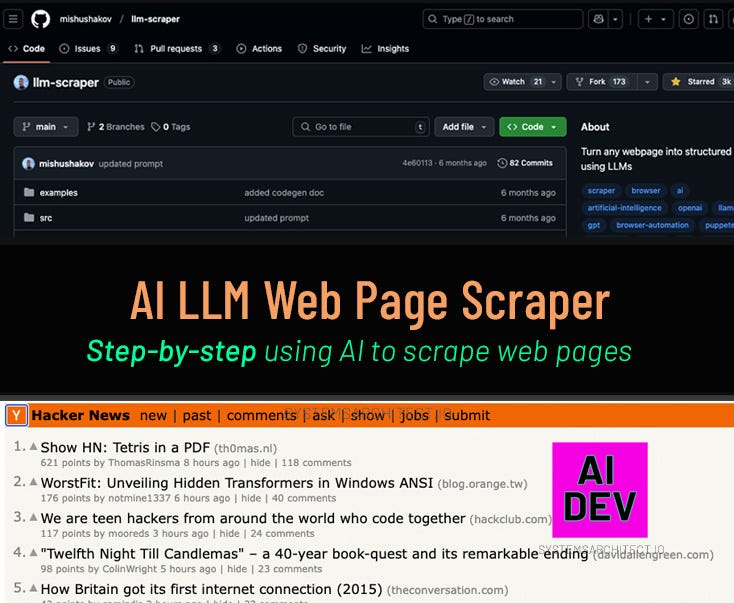
Image Credit: Medium
AI Dev Tips #12: AI LLM Website Scraper review
- The LLM Scraper library simplifies data extraction across various content formats.
- This library supports multiple LLM providers and includes code-generation for re-usable scraping scripts.
- It leverages function calling for precise extraction and can be incorporated into AI Agents and other apps.
- HackerNews and GitHub Trending are used as examples in the tutorial provided in the repo.
- The tutorial highlights the importance of abiding by website terms and not abusing this service.
- A .env file needs to be created to put in the API key environment variables.
- The tutorial also highlights that html scraping may lead to a maximum token size issue that gives an error. Workarounds include changing the format setting in the code from html to another one like format: 'markdown'.
- The library works by defining a schema for extracting structured data.
- The main features of the LLM Scraper library, such as code-generation and data extraction, work and are useful.
- The article also provided information about the author's background and experience in software development.
Read Full Article
2 Likes
For uninterrupted reading, download the app