A naukri.com initiative
Medium
1M
306
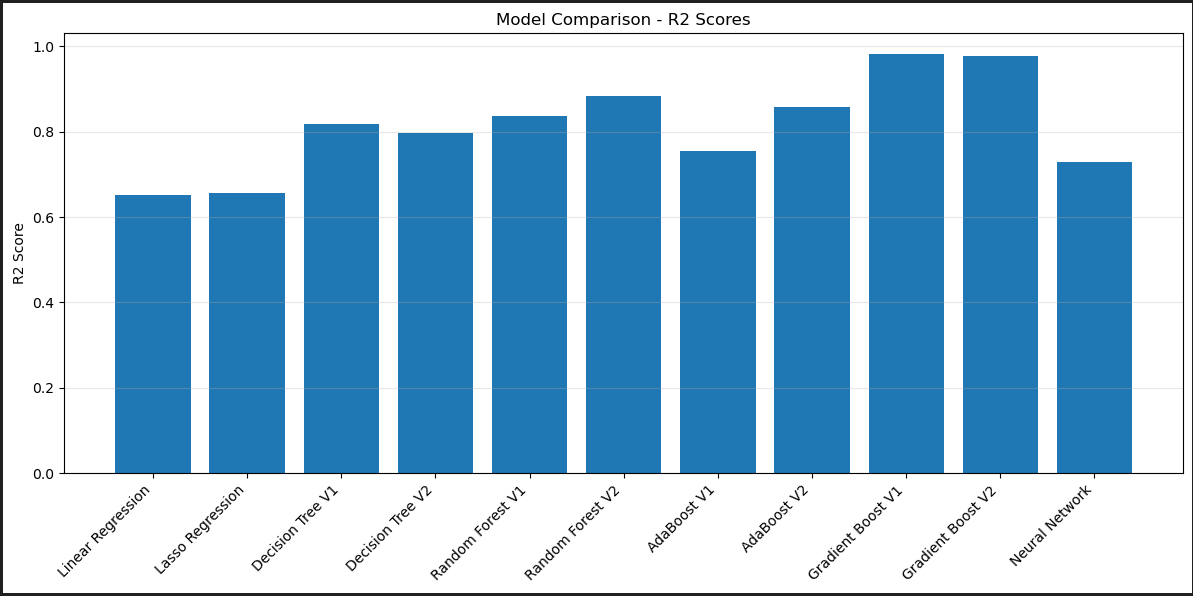
Image Credit: Medium
Beginner Machine Learning Project: Step-by-Step Guide to Predicting London House Prices
- The article provides a step-by-step guide on predicting London house prices using machine learning.
- The dataset used in the project is sourced from Kaggle, and the notebook is available on both Kaggle and GitHub.
- The author recommends following along with the notebook for the complete code.
- The three main steps involve dataset inspection, conversion to numpy, splitting into train and test sets, and normalization of data.
- Data exploration is crucial, including visualizing features and conducting correlation analysis.
- Standard machine learning models are deemed sufficient for the relatively linear dataset; deep learning is not considered necessary.
- Linear Regression initially showed poor results, leading to experimentation with decision tree models like Random Forest.
- Gradient Boosting was found to be the most effective model, providing a solid score that was hard to beat.
- A PyTorch neural network was also implemented, but Gradient Boosting remained the preferred choice due to its performance.
- The article emphasizes the importance of data normalization, understanding model evaluation metrics like r2 score, and optimizing hyperparameters for model performance.
Read Full Article
18 Likes
For uninterrupted reading, download the app