A naukri.com initiative
Medium
1M
99
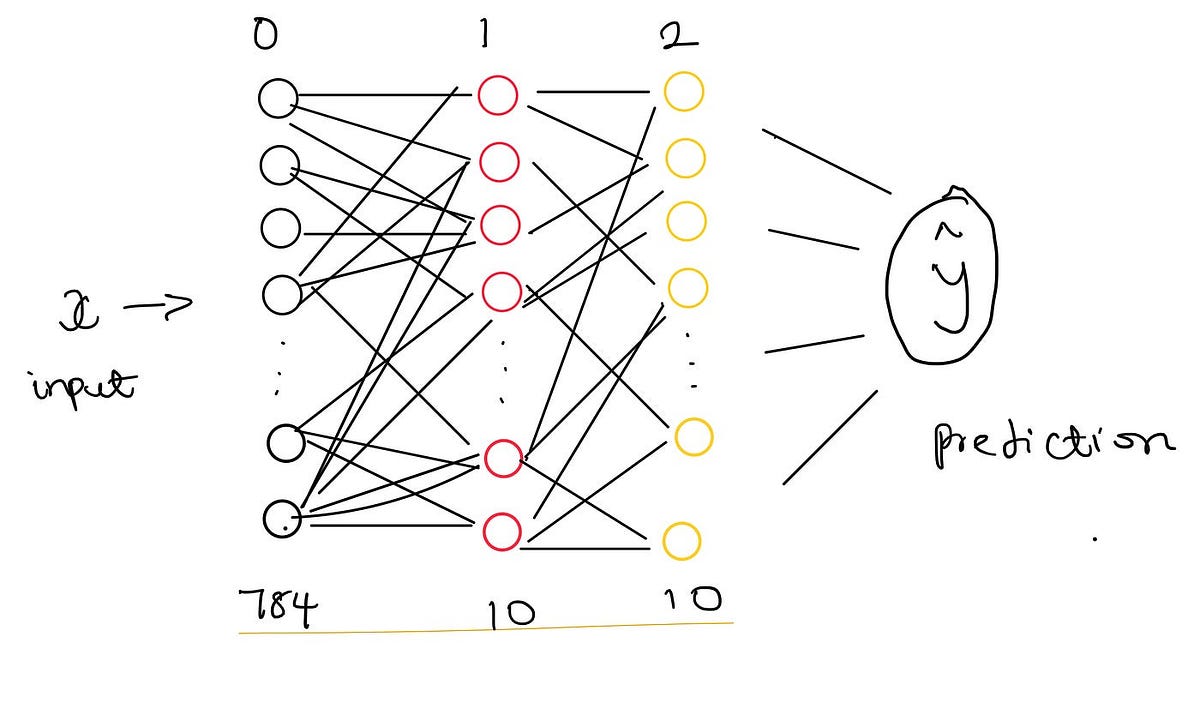
Image Credit: Medium
Build Neural Network from Scratch in Python
- This post covers how to build a simple neural network from scratch that can recognize handwritten digits from the MNIST dataset.
- The MNIST dataset contains 60,000 training images and 10,000 test images of handwritten digits (0–9).
- Each image is flattened into a 784-dimensional vector, which enables us to input directly into our neural network, which has 784 input neurons.
- Our neural network has three layers: an input layer (784 neurons), a hidden layer (10 neurons with ReLU activation), and an output layer (10 neurons with softmax activation).
- The learning process of a neural network involves forward propagation, activation functions, backward propagation, and gradient descent.
- ReLU is an activation function used to introduce non-linearity. It is defined as: ReLU outputs the input ZZ if it is positive, and zero otherwise.
- Softmax is an activation function applied to the output layer to interpret the model’s predictions as probabilities.
- Backward propagation calculates how much each weight and bias contributed to the error in the model’s predictions.
- After calculating the gradients, we use gradient descent to update the parameters, moving in the direction that reduces the network’s error.
- This post demonstrated how to build a simple neural network from scratch in Python to classify MNIST handwritten digits.
Read Full Article
6 Likes
For uninterrupted reading, download the app