A naukri.com initiative
Neural Networks News
Medium
64
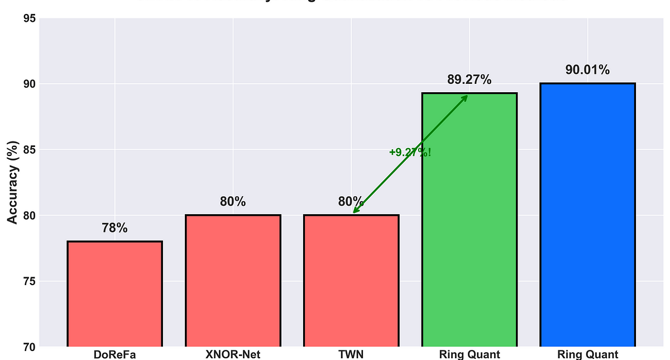
Image Credit: Medium
How I Achieved 89% Accuracy with 2-bit Neural Networks: The Ring Quantization Story
- Efforts are being made to compress neural networks for better accessibility, as current models are too large and resource-intensive.
- A new method called Ring Quantization achieves 89% accuracy with 2-bit networks, a significant improvement over previous methods.
- Ring Quantization allows for 16x compression with less than a 3% drop from full precision, offering promising results for democratizing AI.
- The researcher behind Ring Quantization highlights the potential of the method and aims to further test it on larger models for broader impact.
Read Full Article
3 Likes
Semiengineering
12

Image Credit: Semiengineering
Accelerator Architecture For In-Memory Computation of CNN Inferences Using Racetrack Memory
- Researchers from various institutions have published a technical paper on using racetrack memory for in-memory computing of CNN inferences in embedded systems.
- Racetrack memory is a non-volatile technology that offers high data density fabrication, making it suitable for in-memory computing, but challenges exist in integrating arithmetic circuits with memory cells.
- The paper proposes an efficient in-memory CNN accelerator designed for racetrack memory, including fundamental arithmetic circuits for multiply-and-accumulate operations and co-design strategies to enhance efficiency and performance while maintaining model accuracy.
- The work aims to address the challenges of building efficient in-memory arithmetic circuits on racetrack memory within area and energy constraints, catering to embedded systems for CNN inference.
Read Full Article
Like
Medium
304

5 Basics you NEED to know about Artificial Intelligence(Simplified)
- Machine learning, a subset of AI, allows systems to learn and improve by processing data, with roots tracing back to the 1940s and 50s.
- Deep learning, relying on Artificial Neural Networks, mimics the human brain structure to analyze complex patterns, commonly used in facial recognition.
- Data serves as the fuel for AI systems, crucial for training models and their performance, emphasizing the importance of quality and quantity of data.
- In AI, feeding data is akin to fueling a car, initiating processing similar to engine ignition, resulting in the system producing content after analyzing patterns iteratively.
Read Full Article
18 Likes
Medium
404

Image Credit: Medium
Neural Networks Decoded: How AI Mimics the Human Brain
- Neural networks are complex interconnected nodes inspired by the human brain's ability to learn and adapt, crucial for modern AI systems.
- They consist of layers of interconnected neurons where each neuron processes inputs and sends outputs, allowing the network to learn complex patterns in data.
- Neural networks learn through backpropagation, adjusting connections to optimize performance on tasks, with various types and applications across industries.
- While facing challenges, neural networks revolutionize AI, integrated into AWS services and algorithms to create sophisticated systems improving industries and lives.
Read Full Article
24 Likes
Medium
191
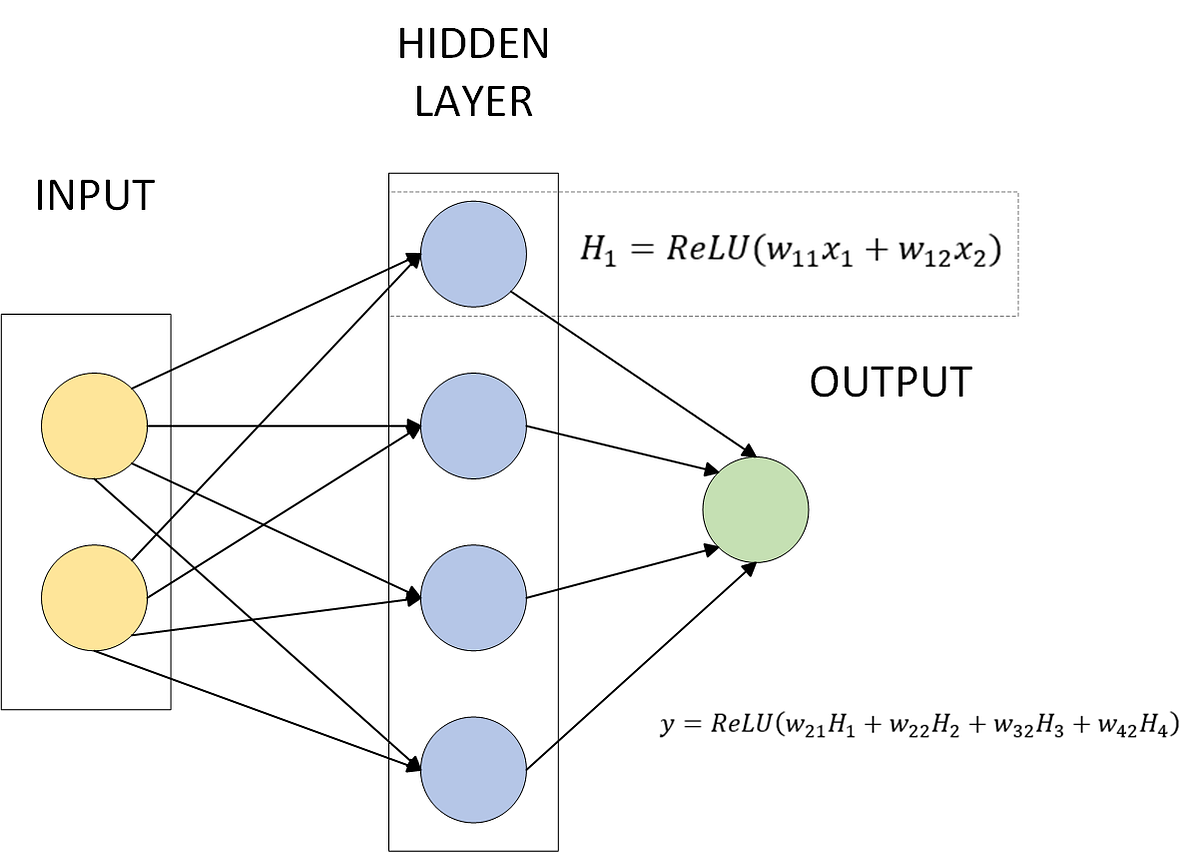
Image Credit: Medium
Neural Nets: Part 1 — Piecewise Linearity
- Neural networks excel in capturing complex non-linear patterns in data by learning flexible, layered representations that adapt to the underlying structure.
- Mathematical foundations laid by pioneers like Joseph Fourier, Taylor, and Weierstrass have contributed to understanding non-linearity, forming the basis for modern machine learning algorithms, particularly neural networks.
- Neural networks break complex patterns down by representing them as piecewise continuous or piecewise linear functions, allowing for more manageable approximations in smaller sub-domains.
- The concept of piecewise linearity can be illustrated using Rectified Linear Unit (ReLU) activation functions, showing how neural networks represent complex non-linear patterns through a sum of several ReLU functions.
Read Full Article
11 Likes
Medium
108

Image Credit: Medium
Let’s Talk About the Work:
- Using AI to predict problematic DNA primer sequences in Loop-mediated Isothermal Amplification (LAMP) tests.
- AI assists in identifying and redesigning primers causing false positives in DNA amplification.
- Advanced techniques like K-mer encoding and 1D CNNs optimize primer design for accuracy.
- Hyperparameter optimization and real-world testing ensure AI reliability and continuous improvement.
- The project showcases AI's potential to enhance molecular biology and diagnostic technologies.
Read Full Article
6 Likes
Medium
323

Reinforcement Learning: Actor-Critic Method for Virtual Highway Environment
- The actor-critic method involves actor and critic entities working together in dynamic environment learning.
- Actor takes actions, receives rewards, enters new state, while critic assesses actor's performance.
- Quantifying agent's performance involves calculating advantages and updating actor and critic policies.
Read Full Article
19 Likes
Medium
157

Image Credit: Medium
Can Artificial Intelligence Replace Journalists?
- AI has revolutionized several dimensions of journalism, automating news stories, analyzing big data, and personalizing content for segmented audiences.
- AI lacks the ability to make ethical judgments, provide critical interpretation, or engage audiences with empathy and nuance.
- The study advocates for a model of symbiosis between journalists and machines, where AI handles repetitive tasks, freeing humans for storytelling, investigation, and ethical decision-making.
- The risks of unregulated AI in journalism include biased data, lack of transparency, spread of misinformation, and the creation of filter bubbles.
Read Full Article
9 Likes
Medium
356
Image Credit: Medium
What happens if we have complex-valued neural networks? A Thought Experiment
- Exploring complex-valued neural networks reveals hidden periodic alter-egos of activation functions.
- Transitioning neural networks to complex numbers introduces challenges with activation function differentiability.
- Complex-Valued Neural Networks (CVNNs) show promise in wave-related fields but face activation function limitations.
- Traditional activation functions like tanh become singular and non-differentiable in the complex plane.
- There is a trade-off between boundedness and differentiability leading to need for specialized functions.
Read Full Article
21 Likes
Medium
181

Image Credit: Medium
Four Applications of Artificial Neural Networks (ANN) for Marketers
- Artificial neural networks proving useful to marketers in various ways.
- They aid in customer segmentation, market analysis, behavior analysis, and sales forecasting.
- Neural networks learn by interpreting patterns, useful in SEO, content recommendations, and ad targeting.
- They offer better customer insights and more relevant content, shaping the future of marketing.
- Marketers embracing AI technologies gain a competitive edge in the evolving landscape.
Read Full Article
10 Likes
Medium
251
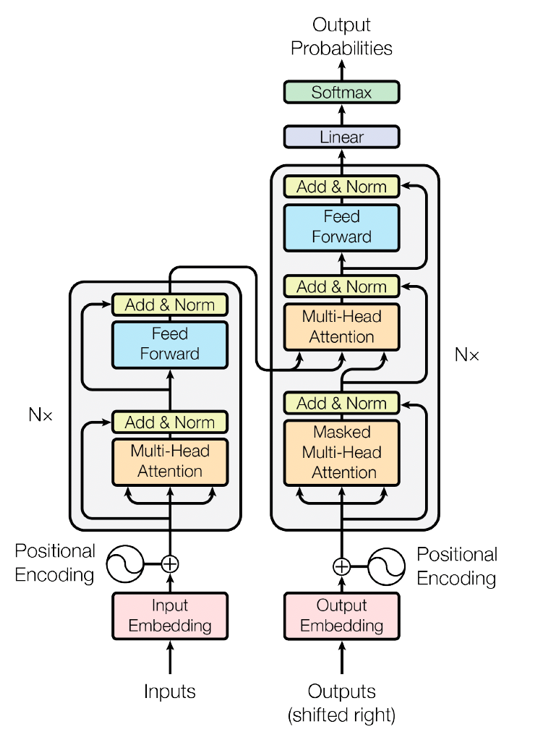
Image Credit: Medium
Transformers in Artificial Inteligence?
- Embeddings in AI convert words or data into numerical vectors for algorithms to understand relationships and context.
- Transformers use positional encoding to maintain the order and relationships between input tokens in natural language processing.
- In a Transformer model, transformer blocks work together using self-attention to understand contextual relationships between words.
- Transformers use linear layers and the softmax function to make predictions based on learned vector representations, turning complex patterns into clear outcomes.
Read Full Article
15 Likes
Medium
114
Image Credit: Medium
10 Common AI Models Explained Simply: From Trees to Neural Networks
- AI models function as decision-making tools in AI systems, each with unique strengths and applications.
- Common AI models include linear regression, used for numerical predictions like house prices.
- Logistic regression is for classification tasks, such as spam detection or loan approval.
- Decision trees operate as flowcharts to make decisions based on yes/no questions.
- Random forests consist of multiple decision trees working together, each contributing to a final decision.
- Support Vector Machines draw boundaries between data categories, useful for tasks like image classification.
- K-Nearest Neighbors algorithm makes decisions based on proximity to other data points.
- Naive Bayes relies on probability and assumes independence of features to classify items like emails.
- K-Means Clustering is an unsupervised model that groups similar data points into clusters.
- Neural Networks are inspired by the human brain and are used in advanced AI applications like image recognition.
- Reinforcement learning models learn through trial and error, receiving rewards or penalties based on their actions.
Read Full Article
6 Likes
Medium
403
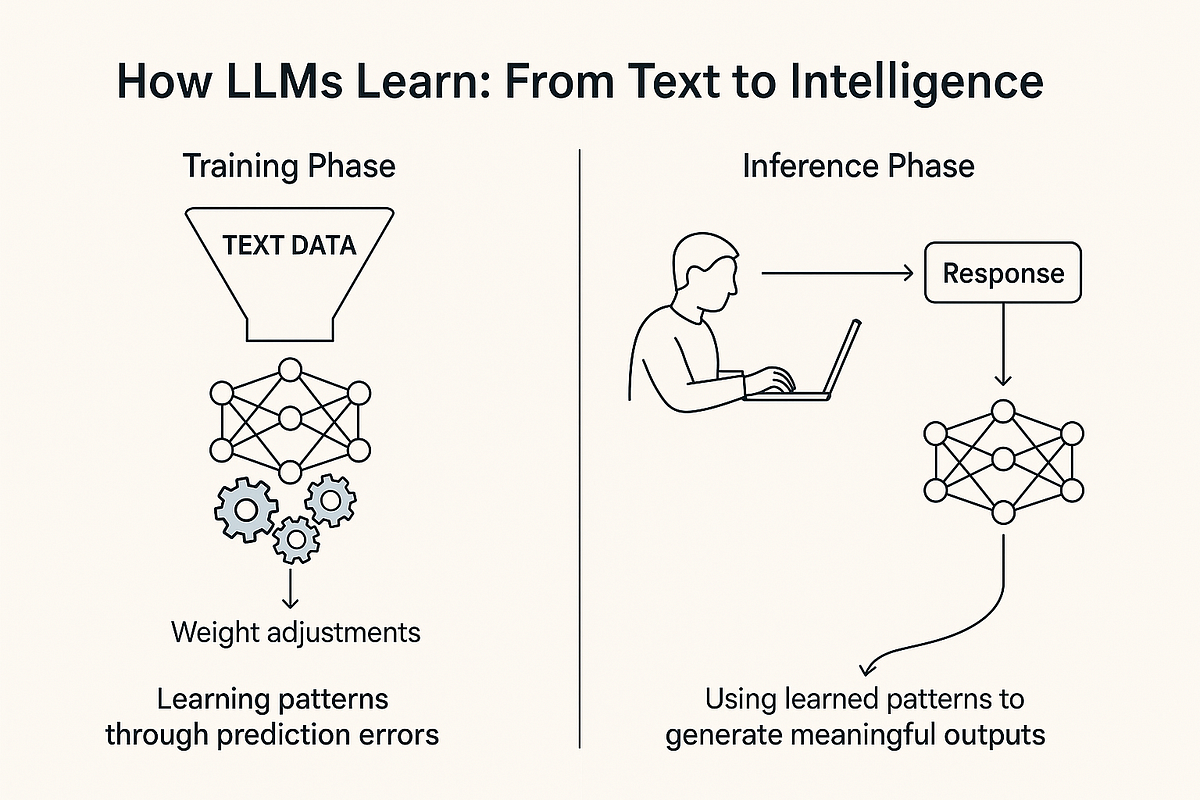
Image Credit: Medium
What the “Model” in LLM Really Means — Explained Simply
- LLM stands for Large Language Model.
- The term 'model' in LLM refers to its ability to predict the next word based on learned statistical patterns in text.
- The model is essentially a trained mathematical function, usually a neural network, that predicts likely text sequences.
- It learns patterns from massive datasets like Wikipedia, books, and articles during training.
- LLMs predict the next word based on statistical pattern recognition but do not have human-like understanding or reasoning.
- The core functionality of LLMs is to predict the next token given prior input during both training and inference.
- Emergent behaviors like summarization, translation, and reasoning are by-products of LLMs' ability to predict text in context.
- LLMs excel in detecting and generalizing patterns in language such as grammar, tone, and reasoning structures.
- The 'model' aspect of LLMs comes from learning statistical relationships between tokens through adjusting weights in neural networks.
- Despite mimicking reasoning patterns, LLMs do not comprehend text like humans; they predict based on probability.
- Text ingestion is different from learning statistical patterns, which is crucial for the model's intelligence.
Read Full Article
24 Likes
Medium
408

Image Credit: Medium
ResNet Paper Explained
- The degradation problem occurs in neural networks as they get deeper, causing performance to deteriorate due to challenges like vanishing gradients and overfitting.
- Deeper networks are harder to train but are important for achieving leading results, like those on the ImageNet dataset.
- A solution to deeper models involves adding identity mapping layers copied from shallower models to prevent higher training errors.
- Learning identity mapping is difficult in neural networks with many nonlinear layers due to the challenges of preserving data perfectly.
- The degradation problem is addressed by introducing a deep residual learning framework in neural networks.
- ResNet introduces a residual connection where F(x) = H(x) - x, allowing the network to naturally learn the residual component to reach the desired output.
- PyTorch implementation of the residual block includes self.block(x) as the residual function and adds the original input back to get the final output.
- The loss function is computed based on the final output, optimizing the residual function F(x) to improve network performance.
Read Full Article
24 Likes
Medium
271

Image Credit: Medium
Welcome to GraphX Lab: Your Visual Guide to Machine Learning and AI
- GraphX Lab focuses on teaching machine learning and AI through a visual approach, emphasizing understanding math visually and intuitively.
- The platform aims to guide learners through core mathematical concepts into practical AI topics.
- Lessons are presented in a visual, practical, and machine learning-focused manner, avoiding traditional dry textbooks.
- The learning experience takes learners from math to model, explaining each step in simple terms.
- MJ, a passionate AI educator, is leading the effort to create a visual-first learning experience, providing insights behind the models.
- GraphX Lab offers a comprehensive learning roadmap more than just a reading list.
- The platform plans to launch Udemy courses, templates, and tools for learners.
- Start with reading 'Why Linear Algebra is the Language of Machine Learning' to kick off the learning journey.
- Follow GraphX Lab to stay updated on new content and learning resources.
Read Full Article
16 Likes
For uninterrupted reading, download the app