A naukri.com initiative
Dev
1M
153
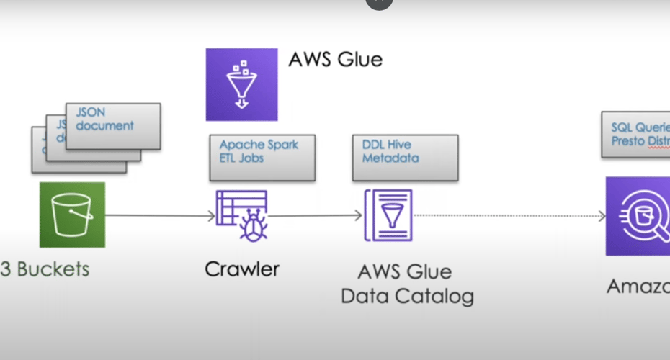
Image Credit: Dev
Building an NBA Data Lake with AWS: A Comprehensive Guide
- This guide shows how to create an NBA Data Lake using Amazon S3, AWS Glue, and Amazon Athena.
- A Python script automates the setup process of creating the data lake.
- Creating a data lake provides a centralized repository of structured and unstructured data at any scale.
- The services used for this project are Amazon S3, AWS Glue and Amazon Athena.
- Amazon S3 is used as the backbone of the data lake, storing both raw and processed NBA data.
- AWS Glue helps manage metadata and schema for the data stored in S3.
- Amazon Athena is used to analyze data stored in S3 using standard SQL.
- CreateBucket, PutObject, ListBucket are the S3 permissions required.
- You can learn about cloud architecture design, data storage best practices, and metadata management using this project.
- Some future enhancements to this project include automated data ingestion, data transformation, advanced analytics, and real-time updates.
Read Full Article
9 Likes
For uninterrupted reading, download the app