A naukri.com initiative
Devops News
Amazon
124
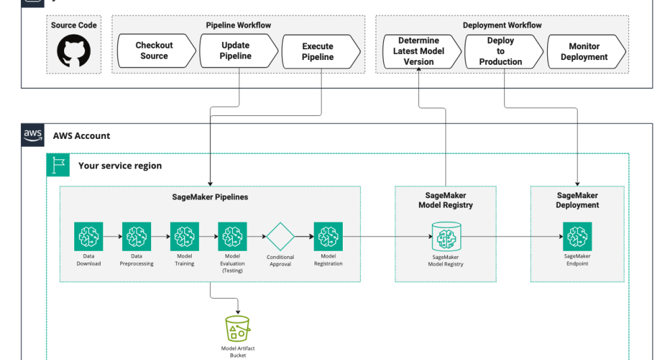
Image Credit: Amazon
How Rapid7 automates vulnerability risk scores with ML pipelines using Amazon SageMaker AI
- Rapid7 enhances vulnerability risk scores with ML pipelines using Amazon SageMaker AI.
- The article details how Rapid7 automates the process for predicting CVSS vectors efficiently.
- Rapid7 utilizes SageMaker AI to build, train, and deploy ML models for CVSS scoring.
- End-to-end automation streamlines model development, deployment, and cost efficiency for Rapid7.
- Automation ensures accurate and timely risk assessment for improved vulnerability management.
Read Full Article
7 Likes
Dev
29

Image Credit: Dev
Secure Shell, Real Power: A Developer’s Guide to SSH
- SSH is a powerful tool for secure communication between computers worldwide.
- It encrypts data, allows remote commands execution, and file transfers securely.
- Key authentication, SSH handshake process, and port tunneling are key components.
- SSH best practices, common commands, troubleshooting, and fun pranks are also covered.
- Responsible use of SSH is crucial for maintaining security in the digital world.
Read Full Article
1 Like
Amazon
43

Image Credit: Amazon
Managing Amazon Q Developer Profiles and Customizations in Large Organizations
- Amazon Q Developer Pro allows organizations to customize AI assistants with proprietary code.
- Teams can efficiently manage access to Amazon Q customizations across regions and Identity Centers.
- Different approaches for implementing and managing Q Developer profiles in large organizations explained.
- Customizations available in US East (N. Virginia) and EU Central (Frankfurt) regions.
Read Full Article
2 Likes
Medium
303

Image Credit: Medium
Web Development in the AI Era Should Version Control Outputs Too
- Version controlling outputs like web snapshots and session replays is proposed to be as crucial as version controlling code in the AI era.
- The complexity of modern development processes makes it challenging to track information scattered across multiple repositories and tools, necessitating a comprehensive approach.
- By version controlling outputs, such as session replays and snapshots, it becomes possible to provide irrefutable evidence of how systems worked at a given time, aiding in verifying AI inferences.
- While facing technical and organizational challenges, the benefits of enhanced information management using session replays and snapshots alongside code version control are believed to outweigh the difficulties.
Read Full Article
18 Likes
Discover more
- Programming News
- Software News
- Web Design
- Open Source News
- Databases
- Cloud News
- Product Management News
- Operating Systems News
- Agile Methodology News
- Computer Engineering
- Startup News
- Cryptocurrency News
- Technology News
- Blockchain News
- Data Science News
- AR News
- Apple News
- Cyber Security News
- Leadership News
- Gaming News
- Automobiles News
Dev
244

Image Credit: Dev
How Kubernetes Calculates Access Permissions Using RBAC Rules
- RBAC in Kubernetes defines access control by determining who can perform actions on resources.
- Authentication in Kubernetes involves validating requests using various methods like client certificates, bearer tokens, or OIDC tokens.
- Authorization in Kubernetes is executed by the RBAC authorizer by evaluating identities against Roles and ClusterRoles defined in the cluster.
- RBAC authorizer matches rules based on verbs, resources, and namespaces to determine access permissions.
Read Full Article
14 Likes
Dev
108

Image Credit: Dev
Why I Built hawk - A CLI Tool That Brings pandas-Like Operations to JSON/YAML/CSV
- An AWS engineer developed hawk, a CLI tool for JSON/YAML/CSV data analysis.
- Hawk simplifies data extraction and analysis tasks with a unified query language.
- It combines the strengths of awk, jq, and pandas, providing flexibility and speed.
- Hawk offers instant structure understanding and supports multiple formats like JSON, YAML, and CSV.
Read Full Article
6 Likes
Dev
87

Image Credit: Dev
What Makes a System Truly Fault-Tolerant?
- A truly fault-tolerant system is one that expects failures and gracefully recovers while maintaining a seamless user experience.
- Key steps to achieve fault tolerance include eliminating single points of failure, using circuit breakers to prevent cascading failures, enabling self-healing mechanisms, ensuring idempotency to avoid duplicate side effects, and implementing graceful degradation strategies.
- Monitoring relevant metrics and alerting actionable events, testing for resilience under stress conditions, preparing for regional outages, and fostering a culture that anticipates failures are vital components of building a fault-tolerant system.
- By following guidelines such as removing SPOFs, utilizing circuit breakers, supporting self-healing processes, maintaining idempotency, handling graceful degradation, and promoting a resilient culture, a truly fault-tolerant system can be developed.
Read Full Article
5 Likes
Dev
847

Image Credit: Dev
Why Your Development Team Is 40% Slower Than Your Competitors (And How to Fix It)
- Your development team might be 40% slower than competitors due to productivity gaps.
- Inefficient workflows, communication chaos, and technical debt contribute to slower feature delivery.
- Implementing focused work blocks, streamlining communication, and automating tasks can boost productivity.
Read Full Article
Like
Dev
118

Image Credit: Dev
Optimizing Cloud Storage for Global Content Delivery and Recovery
- Cloud storage optimization for global content delivery and recovery on Azure involves setting up a robust storage strategy.
- Steps include creating a highly available storage account named 'publicwebsite' with read-access geo-redundancy and anonymous public access for web content.
- Organizing content in a blob storage container, configuring anonymous read access, practicing file uploads, enabling soft delete for easy file recovery, and setting up blob versioning are critical elements of the optimization process.
- The article provides detailed instructions on implementing these key features to ensure data accessibility, security, and historical integrity for websites hosted on Azure cloud storage.
Read Full Article
7 Likes
Dev
149

Image Credit: Dev
How to Secure SSH Access with Short-Lived Certificates
- SSH keys provide a secure way to access remote servers without passwords but do not have expiration dates, posing a security risk if compromised.
- Signing Certificate Authority allows for creating short-lived certificates to enforce expiration dates on SSH access for enhanced security.
- Steps to create expiring SSH keys involve setting up a CA key on the server, configuring the local device, and generating and signing user SSH keys.
- Using expiring SSH keys enhances security by minimizing potential damage if keys are compromised and fits well with Just-in-Time access tools for increased server security.
Read Full Article
8 Likes
Dev
138

Image Credit: Dev
The Hidden Realities of Cloud Migration: Lessons from the Trenches
- In theory, cloud migration seems straightforward with assessment, planning, and execution.
- Real-world cloud migration poses challenges like dependency gaps and unexpected issues.
- Lessons learned include cost optimization, handling legacy systems, and collaboration insights.
- Recommendations stress validating tools, pre-migration reboots, and thorough documentation for success.
- Cloud migration is a complex process requiring adaptability, planning, and collaboration for success.
Read Full Article
8 Likes
Dev
22

Image Credit: Dev
Serve Static React Files with NGINX in a Multi-Stage Docker Build
- The article discusses how to serve a React app, specifically a custom build, using a multi-stage Docker build and NGINX to efficiently serve static files.
- The process involves building the app in a Docker container, extracting the static files, such as SSR output, and configuring NGINX to serve these files at a specific path.
- The multi-stage Dockerfile includes stages for building the app and serving it with NGINX. The NGINX config specifies how to serve the static output, mapping paths, and ensuring strict routing.
- This setup is recommended for deploying custom SSR builds, serving lightweight screens, isolating app parts to different subpaths, and eliminating the need for Node.js to run in production, resulting in smaller images and faster starts.
Read Full Article
1 Like
Dev
120

Image Credit: Dev
Kubernetes Feels Complicated. It's Time To Fix That.
- Kubernetes is a powerful tool but can feel complex and overwhelming for beginners in the tech community.
- A new series, 'Kubernetes: From Zero to Hero,' aims to simplify Kubernetes learning by providing clear, practical, and accessible guidance.
- The series will focus on hands-on exercises, include all necessary resources in each post, and build knowledge progressively.
- The series roadmap includes topics from basic concepts to advanced topics, with the goal of becoming a comprehensive Kubernetes resource.
Read Full Article
7 Likes
Medium
254

Image Credit: Medium
Docker and the Moment the World Needed It
- Shipping software before Docker was challenging and time-consuming, requiring manual configurations and custom tools.
- Docker revolutionized software shipping by providing a standardized way to package, execute, and network applications.
- Docker's core components included packaging with Docker images, predictable execution with container runtime, and a basic networking model.
- The Docker team continued to innovate with features like Docker Compose for multi-container systems and clustering solutions like Docker Swarm and Kubernetes.
Read Full Article
15 Likes
Dev
175

Image Credit: Dev
How to provide shared file storage for the company offices.
- Smooth collaboration between company offices in today’s digital workplace is crucial for productivity.
- Setting up shared file storage across offices involves creating and configuring a storage account for Azure Files.
- Steps include creating a storage account, setting up file shares with directories, configuring and testing snapshots, and restricting storage access to selected virtual networks.
- These steps ensure fast, secure, and reliable access to shared files for teams in different locations.
Read Full Article
9 Likes
For uninterrupted reading, download the app