A naukri.com initiative
Medium
2w
210
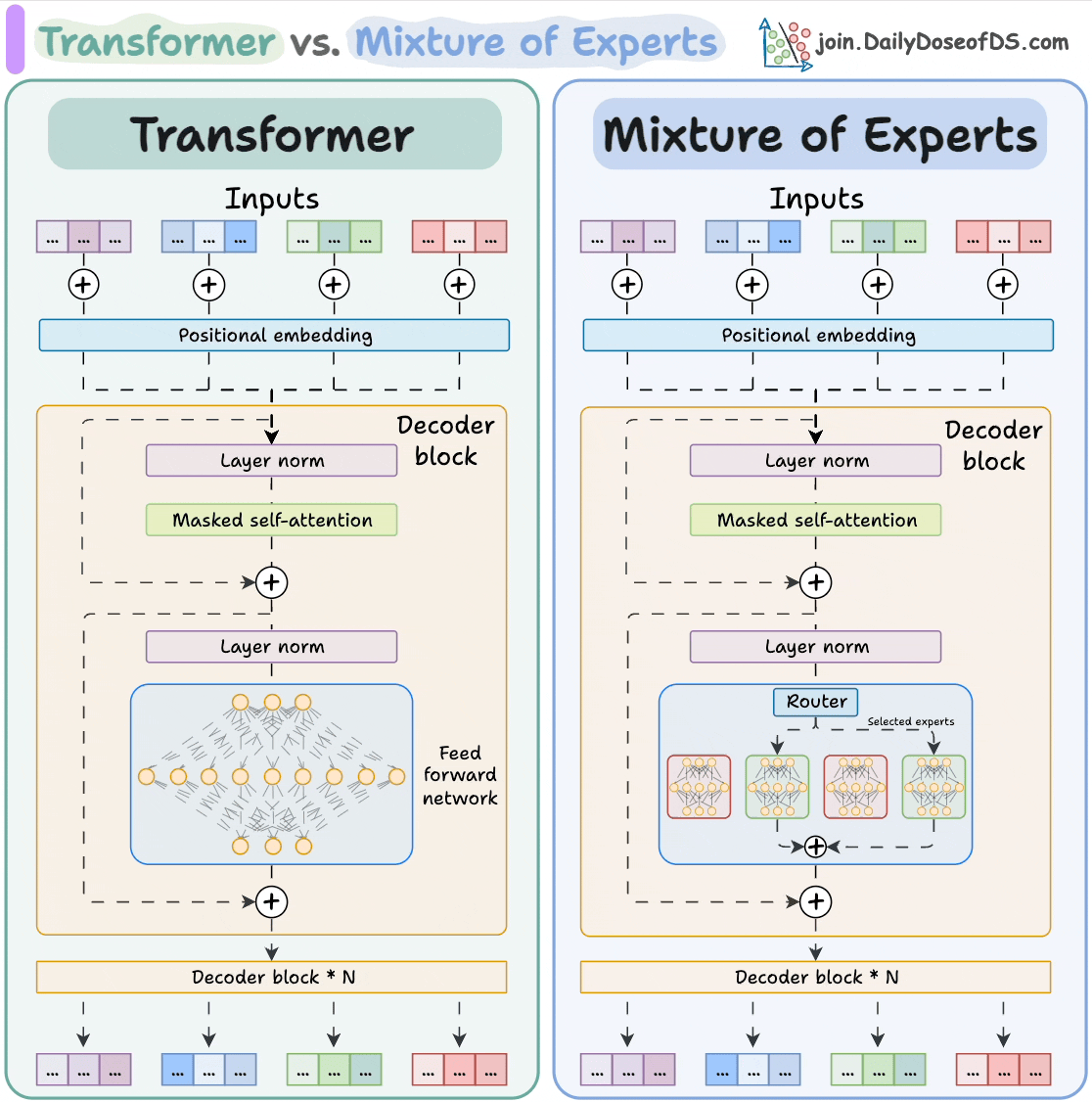
Image Credit: Medium
Demystifying Mixture-of-Experts (MoE) Layers
- Mixture-of-Experts (MoE) layers activate only a fraction of the feed forward network per token compared to Dense Transformers, resulting in computational efficiency and model capacity enhancement.
- MoE architecture consists of Experts and a Router or Gating Network to enhance model efficiency.
- A key component of MoE is Noisy Top-K Gating, a mechanism routing input tokens to a subset of experts based on learned noise, promoting load balancing and exploration.
- Maintaining an optimal Computation-to-Communication Ratio in MoE models, achieved through increasing hidden layer size, is crucial for scaling across data centers efficiently, overcoming network bandwidth limitations.
Read Full Article
12 Likes
For uninterrupted reading, download the app