A naukri.com initiative
Amazon
3w
416
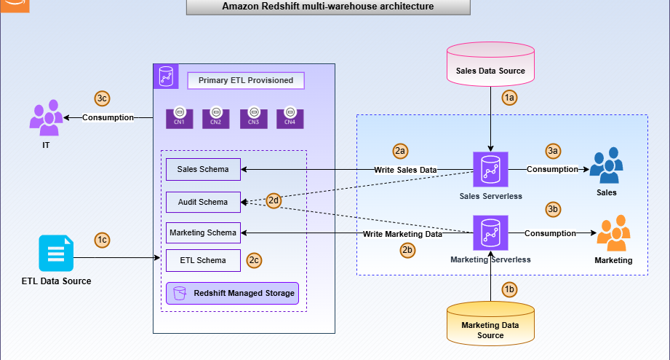
Image Credit: Amazon
Develop a business chargeback model within your organization using Amazon Redshift multi-warehouse writes
- Amazon Redshift is a cloud data warehouse that allows customers to scale read workloads without copying data
- The multi-data warehouse writes feature supports scaling write workloads on different warehouses based on workload needs
- Benefits of this feature include cost monitoring and control for each data warehouse and enabling data collaboration
- The solution architecture presented involves setting up separate workgroups for ingestion and consumption and creating datashares for different business units
- The chargeback model allows for attributing costs to different business units and implementing cost control optimizations
- Prerequisites include having 3 Redshift warehouses, a superuser in each warehouse, and an IAM role to ingest data from Amazon S3 to Redshift
- Steps involve setting up primary ETL cluster, creating datashares, granting object permissions, and setting up Sales and Marketing warehouses
- The chargeback calculation is based on compute capacity utilization measured in Redshift Processing Units (RPUs)
- Cleaning up involves deleting Redshift provisioned cluster, serverless workgroups, and namespaces
- The benefits of the solution include straightforward cost attribution, using different clusters and data warehouses, writing data even when producer warehouse is paused, and working across accounts and Regions
Read Full Article
25 Likes
For uninterrupted reading, download the app