A naukri.com initiative
Big Data News
Siliconangle
226

Image Credit: Siliconangle
Aerospike unveils native Rust client preview, targeting real-time ‘safe’ applications
- Aerospike Inc. has released a preview version of a fully supported Rust client for developers building high-throughput, low-latency applications.
- The Rust client includes features like async support, advanced queries, batch operations, and rack-aware policies.
- The client aims to achieve feature parity with other official clients, such as those for Go, Java, and C#, by 2025 and seeks ongoing community feedback for further improvements.
- The release of the Rust client marks a shift towards a production-grade library maintained by Aerospike, with a roadmap for general availability in 2025 including documentation and examples on GitHub.
Read Full Article
13 Likes
Amazon
64
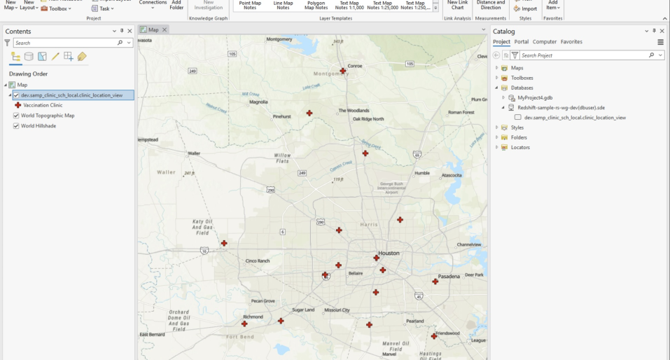
Image Credit: Amazon
Geospatial data lakes with Amazon Redshift
- Offload data to data lake architectures to query and analyze geospatial data cost-effectively.
- Amazon Redshift supports querying and accessing geospatial data from both data lakes and warehouses.
- Tutorial explains setting up geospatial data lake using Lake Formation and ArcGIS Pro.
- Includes steps like AWS CloudFormation deployment, Lake Formation permissions, and Redshift setup.
Read Full Article
3 Likes
Siliconangle
190
Image Credit: Siliconangle
Datafy raises $20M in seed funding to optimize cloud storage costs autonomously
- Datafy Inc. secures $20M in seed funding for cloud storage optimization tool.
- The startup's platform autonomously reduces cloud storage costs, compatible with AWS.
- Datafy's approach is non-disruptive, manually adjusting storage volume sizes for efficiency.
- The funds will aid U.S. expansion and development of enhanced storage optimization tools.
Read Full Article
11 Likes
Amazon
32

Image Credit: Amazon
Near real-time baggage operational insights for airlines using Amazon Kinesis Data Streams
- Baggage operational insights are crucial for airlines to optimize efficiency and passenger experience.
- Real-time analytics using AWS services can enhance decision-making, predictive maintenance, and operational costs.
- Modernization involves breaking down monolithic databases, streamlining data transfer, and using cloud-based solutions.
- Proposed AWS architecture includes Kinesis Data Streams, DynamoDB, Aurora for robust real-time analytics.
Read Full Article
1 Like
Siliconangle
280

Image Credit: Siliconangle
Graphwise enhances its graph database to become the brains of AI agents
- Bulgarian startup Graphwise upgrades its flagship GraphDB tool for AI applications.
- Improvements aim to boost enterprise knowledge management and support AI models.
- New features in GraphDB 11 include LLM integration and precision entity linking.
Read Full Article
16 Likes
Amazon
78

Image Credit: Amazon
Overcome your Kafka Connect challenges with Amazon Data Firehose
- Apache Kafka is widely used in AWS ecosystem for real-time data streams.
- Amazon MSK simplifies managing Kafka clusters, offering fully managed services and provisioning.
- Amazon Data Firehose integration with MSK provides a serverless solution for data delivery.
- Firehose stream can now read from custom timestamps, easing migration and data delivery.
- Data Firehose automates scaling, error handling, direct delivery to S3 with simplified configuration.
Read Full Article
4 Likes
Amazon
103

Image Credit: Amazon
How Stifel built a modern data platform using AWS Glue and an event-driven domain architecture
- Stifel Financial Corp. modernized its data platform using AWS Glue and event-driven architecture.
- The platform offered accurate, timely, and governed data, overcoming complexity and increasing demand.
- AWS Glue, Amazon EventBridge, AWS Lake Formation, and Apache Hudi were key services.
- The event-driven architecture allows real-time updates and caters to scalability and agility.
Read Full Article
6 Likes
Amazon
290

Image Credit: Amazon
Harnessing the Power of Nested Materialized Views and exploring Cascading Refresh
- Amazon Redshift materialized views enhance query performance with precomputed results for future use.
- Materialized views are beneficial for speeding up predictable queries and offer significant performance gains.
- Nested materialized views in Amazon Redshift create a hierarchy of precomputed results for efficiency.
- Cascading refresh option in materialized views helps maintain data consistency and optimize performance.
Read Full Article
17 Likes
Siliconangle
393

Image Credit: Siliconangle
From dashboards to decisions: How AWS is transforming data access at scale
- Interactive data insights redefine how businesses make decisions in real time.
- Amazon QuickSight offers intuitive BI, AI-driven analytics for users at all skill levels.
- AWS revolutionizes data access with dynamic tools, empowering organizations with agile insights.
Read Full Article
23 Likes
Amazon
264

Image Credit: Amazon
Develop and monitor a Spark application using existing data in Amazon S3 with Amazon SageMaker Unified Studio
- Managing big data analytics workloads is a challenge for organizations, leading to inefficiency.
- Amazon SageMaker Unified Studio with Amazon EMR addresses these issues for enterprises.
- The solution involves creating EMR Serverless compute environments, developing Spark applications, and monitoring.
- The integrated environment streamlines analytics workflow, offering cost-efficiency and seamless monitoring capabilities.
Read Full Article
15 Likes
Amazon
322

Image Credit: Amazon
Perform per-project cost allocation in Amazon SageMaker Unified Studio
- Amazon SageMaker Unified Studio is a single data and AI development environment.
- You can create domains and projects in SageMaker Unified Studio for end-to-end workflows.
- Implement cost allocation tags to track and allocate costs for resources in SageMaker.
- Follow steps to configure cost allocation tags and monitor costs using AWS tools.
Read Full Article
19 Likes
TechBullion
130

Image Credit: TechBullion
Rahman Shittu: The Data Science Powerhouse Redefining Innovation in the US and Beyond
- Rahman Shittu, a data powerhouse, redefines innovation in US and globally.
- His journey from Nigeria to pursuing data science reshapes sectors worldwide.
- Research on healthcare, e-commerce, cybersecurity, and smart cities show global impact.
- Rahman's work blends technical expertise with ethical responsibility for a brighter future.
Read Full Article
7 Likes
Siliconangle
224

Image Credit: Siliconangle
Snowflake supercharges Cboe’s analytics and monetization at financial-market scale
- Cboe Global Markets Inc., operating at a massive data scale, has partnered with Snowflake to supercharge its analytics and monetization capabilities.
- Cboe's analytics stack transitioned to Snowflake and Sigma Computing, enabling a strong data foundation and supporting downstream analytics.
- Snowflake emphasizes modernizing data infrastructure to unlock AI's potential, aligning technology investments with business priorities and focusing on data trust and governance.
- The partnership between Cboe and Snowflake aims to meet the increasing demands for quicker insights and decision intelligence in the financial industry.
Read Full Article
13 Likes
Amazon
55

Image Credit: Amazon
Build conversational AI search with Amazon OpenSearch Service
- Retrieval Augmented Generation (RAG) enhances generative AI applications through external knowledge retrieval.
- Amazon OpenSearch Service is used with RAG to provide accurate, personalized AI responses.
- Conversational search architecture with ML models optimizes user interaction and information retrieval.
- Integration of agents, tools, and ML models in OpenSearch boosts conversational AI efficiency.
Read Full Article
3 Likes
Amazon
118

Image Credit: Amazon
Enhance stability with dedicated cluster manager nodes using Amazon OpenSearch Service
- Amazon OpenSearch Service offers dedicated cluster manager nodes for enhanced stability and performance.
- Dedicated manager nodes handle cluster management tasks without impacting data node performance.
- Configuring dedicated cluster manager nodes can improve cluster stability, reliability, and performance.
- Having three dedicated cluster manager nodes is recommended for production use cases.
- It's important to monitor and adjust cluster manager instance type for optimal performance.
Read Full Article
7 Likes
For uninterrupted reading, download the app