A naukri.com initiative
Medium
18h
229
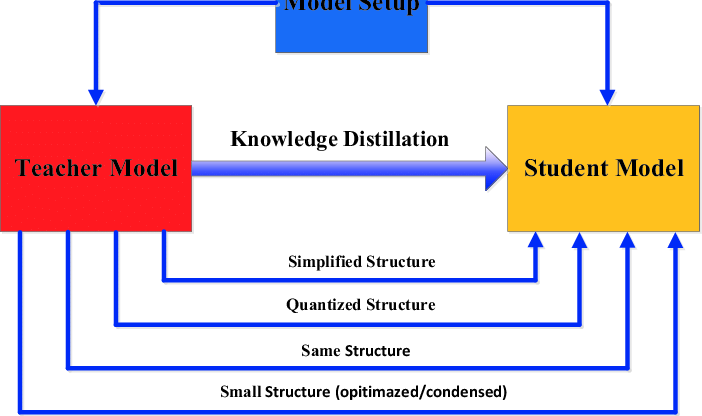
Image Credit: Medium
Distilling Intelligence: Simplifying Machine Learning Models
- Model distillation, also known as knowledge distillation, is a process where a large 'teacher' model transfers its knowledge to a smaller 'student' model.
- The distillation process involves training the student model to mimic the teacher model's behavior by learning from its predictions or internal representations.
- Types of distillation methods include offline distillation, online distillation, and self-distillation, catering to different needs.
- Model distillation has applications in natural language processing, computer vision, and edge computing, offering benefits such as reduced model size, lower computational costs, and faster inference speeds.
Read Full Article
13 Likes
For uninterrupted reading, download the app