A naukri.com initiative
Medium
7d
266
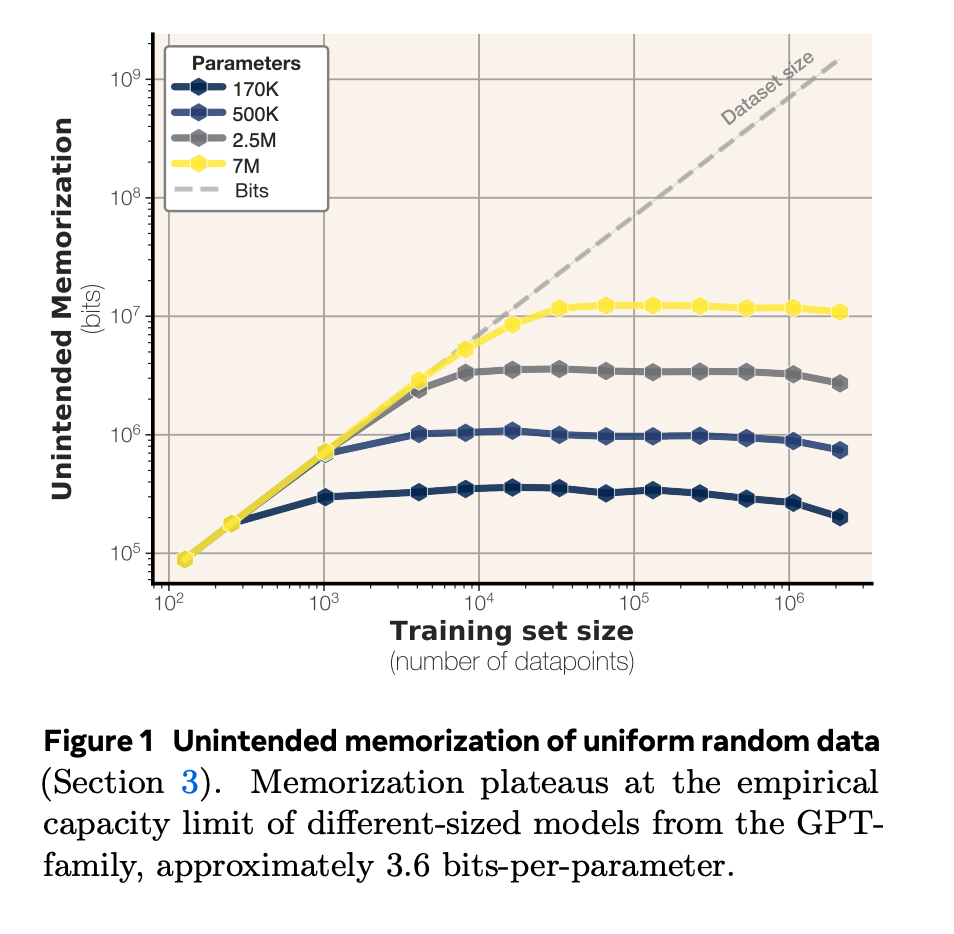
Image Credit: Medium
Does a LLM Memorize Private or Sensitive Data from Training?
- Researchers from Meta, DeepMind, Cornell, and NVIDIA released a paper titled 'How Much Do Language Models Memorize?' in June 2025.
- The paper introduces a framework for measuring memorization in language models and its relation to model size, data scale, and privacy risk.
- It proposes an information-theoretic definition of memorization grounded in Kolmogorov complexity, separating memorization from generalization.
- The study examined transformer models on synthetic and real text data to understand how models memorize and transition to generalization as datasets grow.
Read Full Article
16 Likes
For uninterrupted reading, download the app