A naukri.com initiative
Medium
2w
111
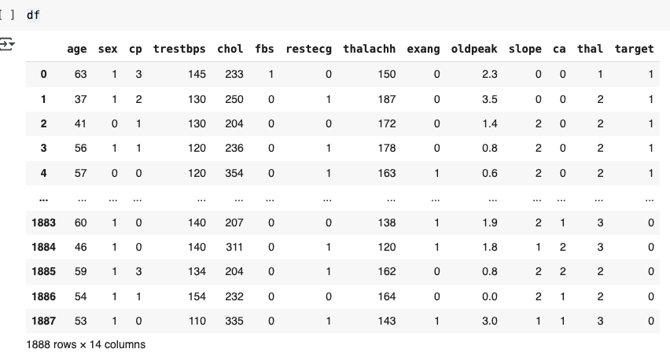
Image Credit: Medium
Experimenting with ML: Trying out Different Algorithms for One Simple Task
- To create a model for predicting heart disease, the first step is to find and download a dataset, such as the 'Heart Disease Dataset' from Kaggle.
- Loading the dataset into an IDE like Google Colab can be done by mounting it from Google Drive to avoid re-uploading.
- By using Pandas DataFrame, the dataset is stored and ready for manipulation in the Colab environment.
- Data preparation for model training involves splitting the dataset into training and testing sets.
- X is set to feature data, while y represents the target column indicating heart disease presence.
- Models tested include Logistic Regression, Support Vector Machines, Random Forests, XGBoost, Naive Bayes, and Decision Trees.
- Evaluation of model performance shows Random Forest as the most accurate for heart disease prediction in this case.
- Different models may perform better based on data complexity and problem type, so experimenting with various algorithms is crucial.
- Experimenting with different machine learning algorithms helps in determining the best fit for specific tasks and datasets.
- Each machine learning model has its strengths, and the choice of algorithm depends on the problem being addressed.
- The article concludes by emphasizing the importance of trying multiple models and tuning hyperparameters to find the optimal solution.
Read Full Article
6 Likes
For uninterrupted reading, download the app