A naukri.com initiative
Medium
1M
312
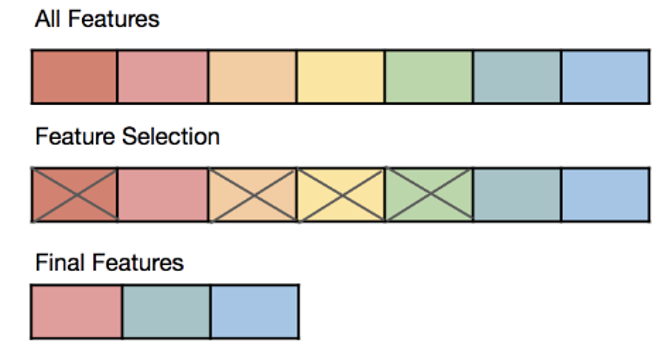
Image Credit: Medium
Feature Selection Part 1: Choose Wisely, Predict Better
- Feature Selection is the process of choosing the most relevant input variables (features) from your dataset that contribute the most to the output variable.
- Feature selection improves model accuracy by minimizing noise and reducing overfitting.
- Filter methods, such as removing duplicates, using variance thresholds, checking correlations, and applying statistical tests like ANOVA and Chi-Square, are commonly used for feature selection.
- In the next chapter of 100 Days of Machine Learning, the focus will be on Wrapper Methods, where machine learning models guide the selection of features.
Read Full Article
18 Likes
For uninterrupted reading, download the app