A naukri.com initiative
Towards Data Science
1M
104
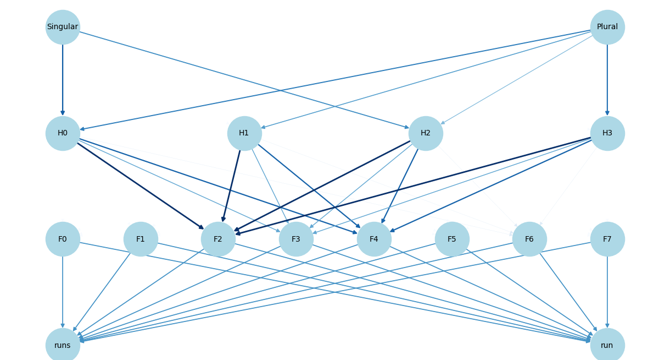
Image Credit: Towards Data Science
Formulation of Feature Circuits with Sparse Autoencoders in LLM
- Feature circuits are how networks learn to combine input features to form complex patterns at higher levels.
- In the context of Machine Learning, Sparse Autoencoders (SAEs) help disentangle the model's activations into a set of sparse features.
- The study focuses on building a feature circuit in LLMs for a subject-verb agreement task.
- Feature circuits provide insights into the decision-making process of a complex LLM and can be formed using SAEs.
Read Full Article
5 Likes
For uninterrupted reading, download the app