A naukri.com initiative
Medium
1M
250
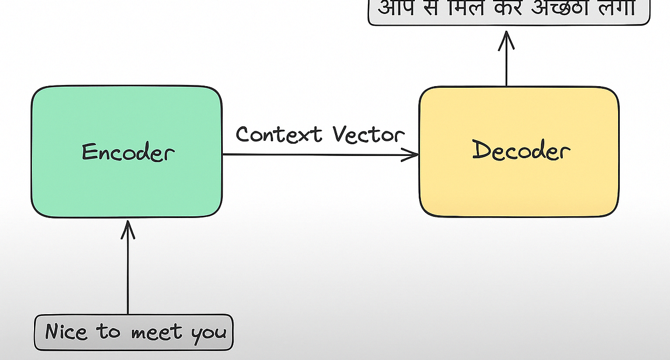
Image Credit: Medium
From Input to Output: Demystifying the Encoder-Decoder Architecture
- The Encoder-Decoder architecture is a two-part neural design used in tasks like machine translation, speech recognition, and text summarization.
- Predecessors like RNNs struggled with tasks where output structure did not directly align with inputs, leading to the development of the Encoder-Decoder model.
- The Encoder-Decoder framework comprises an encoder that processes input sequences and produces a context vector, and a decoder that generates output sequence based on this vector.
- During training, the decoder uses teacher forcing, and during inference, relies on its previous predictions to generate the output.
- The architecture allows handling variable-length sequences and has been pivotal in NLP advancements like machine translation and text summarization.
- The Encoder-Decoder model laid the foundation for attention mechanisms and transformer models, enhancing memory handling and flexibility.
- Introduction of attention mechanism addressed context bottleneck issues by enabling the decoder to focus on relevant parts of the input.
- Transformers, a product of this evolution, have revolutionized AI models like GPT, BERT, and T5, replacing recurrence with parallelism and scale.
- By separating comprehension (encoder) and generation (decoder), the architecture brought structure and scalability to tasks like translation and summarization.
- The Encoder-Decoder architecture sparked a new era in deep learning, revamping how sequences are processed and generated in modern AI models.
Read Full Article
15 Likes
For uninterrupted reading, download the app