A naukri.com initiative
Medium
3w
92
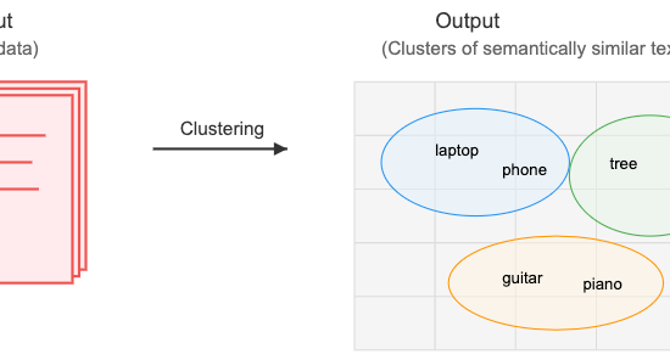
Image Credit: Medium
From Text to Insights: Hands-on Text Clustering and Topic Modeling with LLMs — Part 1
- This article introduces text clustering and its application in identifying clusters of related topics without manual reading of thousands of research abstracts.
- The article discusses the process of converting text into numerical representations using embedding models, selecting a suitable clustering model (stella-en-400M-v5), and reducing the dimensionality using UMAP.
- Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) is used to cluster the reduced embeddings, resulting in 159 clusters.
- The clusters are validated through manual inspection and 3D visualization, showcasing the successful organization of 44,949 arXiv NLP papers into semantically coherent groups.
Read Full Article
5 Likes
For uninterrupted reading, download the app