A naukri.com initiative
Towards Data Science
2d
71
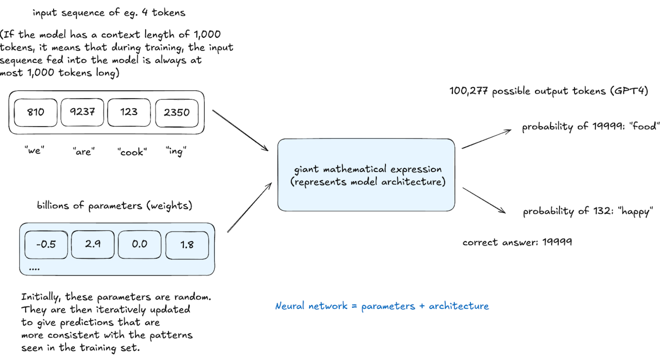
Image Credit: Towards Data Science
How LLMs Work: Pre-Training to Post-Training, Neural Networks, Hallucinations, and Inference
- LLMs go through pre-training and post-training phases to learn how language works.
- Pre-training involves gathering diverse datasets like Common Crawl and tokenization.
- Tokenization converts text into numerical tokens, essential for neural network processing.
- Neural networks predict the next token based on context, adjusting parameters through backpropagation.
- Post-training fine-tunes LLMs on specialized datasets to improve performance.
- Inference evaluates model learning by predicting next tokens based on training.
- Hallucinations occur when LLMs predict statistically likely but incorrect information.
- Improving factual accuracy requires training models to recognize knowledge gaps.
- Self-interrogation and fine-tuning help LLMs handle uncertainties in responses.
- LLMs can access external search tools to extend knowledge beyond training data.
Read Full Article
3 Likes
For uninterrupted reading, download the app